こんにちは。研究開発室の北村 蘭丸です。研究開発室では、Operations Research (OR) のビジネス活用について研究を進めています。本記事では、その一環として現在取り組んでいる機械学習による製造機器の予知保全についてご紹介いたします。
続きを読むAWSを使用したDatabricksの環境構築
こんにちは。研究開発室の東です。
今回はDatabricksを使用する際の作業領域であるワークスペースを手動で構成する方法について解説します。 本稿では、ワークスペースを構築するために必要なクラウドサービスにはAWSを使用し、S3、IAMロール、VPCなどの必要なリソースの作成にはAWS CDKを使用します。
本稿では、以下の点を取り扱います。
想定される読者は、以下のような方々です。
- Databricksの導入(premium plan以上・クラウドにAWSを使用)を考えている方
- Databricksに必要なAWSのリソースを手動で作成したい方
- CDK/ CloudformationでDatabricksに必要なクラウドリソースを一括で管理したい方
Agentforce へのリブランディングに伴う Copilot の仕様の変化
こんにちは。エンジニアの山下です。
先日行われた Dreamforce 2024 の目玉として Agentforce が大きく取り上げられました。その一環として Einstein Copilot は Agent の一種として取り扱うという階層変更が行われ、またこれに伴い8月末から9月初頭にかけて一部の仕様が変更されています。
この仕様変更の中には Einstein Copilot の開発工程に大きく影響を与えるものが含まれており、その筆頭が Agent Topics の追加です。端的に述べると、これは既存の Copilot と Action の間に階層を一つ追加するような変更で、開発に対して設計レベルの影響があります。
この Agent Topics の追加により、これまで当ブログに書いてきた Einstein Copilot の記事の内容が古くなってしまったわけで、これはいただけない状況です。というわけで、今回は Agent Topics について書きたいと思います。
続きを読むDatabricks を活用した機械学習プロジェクトの PoC フェーズの高速化に向けた取り組みの紹介
こんにちは,研究開発室の福井です.研究開発室においてオペレーションズ・リサーチ(OR)のビジネス活用について研究を行っております.今回は,機械学習プロジェクトを高速化するために現在研究開発室で推進している取り組みについてご紹介します.
続きを読むマルチモーダル LLM と OCR + LLM を比較してみる
こんにちは。エンジニアの山下です。今回は OCR について書こうと思います。
OCR は画像中の文字を文字データに変換するシステムの総称で、DX の前段階にあたるペーパーレスの推進などの文脈でしばしば見かけます。昨今の AI ブームの恩恵を受けて OCR の精度は非常に高くなっており、実際、以下のように粗悪な質の画像であってもそれなりの精度で機能します。

しかし、DX の前段階という文脈では、単に OCR の読み取り精度が高いだけでは十分とは言えません。というのは、多くの場合、OCR の出力は構造化されたデータではなく、読み取った文字列を列挙しただけのデータ片になりがちだからです。
以下に実際の OCR の出力から一部を抜粋したものを示します。
金額 NO. 数量 単価 10,000 1 1,000 2 0000002 · 用紙2 15 500
この問題は特に表データなどを含む画像において顕著で、これではデータに十分な質を要求する DX の第一歩としては不十分と言わざるを得ないでしょう。
この問題への対処方法の1つに OCR の出力を LLM を使って整理するという方法があります。非構造化データの構造化は LLM が得意とする仕事の1つなので、それなりの精度で紙データを適切な電子データに変換できそうという期待があります。
一方で、LLM を使うのであれば、マルチモーダル LLM を使って画像を直接 LLM に入力して電子データに変換するという方法も考えられます。OCR の出力を受け取るパイプラインを構築せずに済むので、開発工数上はこちらの方が有利そうですね。
こうして LLM を使った紙データの電子データ化の方法が2つ挙がったわけですが、2つ並ぶとどちらの方法がよいのかが気になるところです。というわけで、今回はこの2つの方法を比較検証してみます。
続きを読むEinstein Copilot で商談案件のリスクを評価する
こんにちは。エンジニアの山下です。
今回は Einstein Copilot のユースケースの一例として、Einstein Copilot を使って商談案件のリスクの評価を行う方法について書きたいと思います。
商談案件の状況の追跡は Salesforce をはじめとする CRM プラットフォームが取り組む大きな課題の1つです。商談案件を管理する立場にある人、特に複数の案件を管理する立場にある人には、案件の状況を手早く確認し、かつ介入が必要かどうかを正確に判断できるような手段が欲しいという強いニーズがあります。
実はこのニーズには Eisntein Copilot がピタリと嵌まります。抽象的な状況の要約は LLM が最も得意とするタスクの1つであり、また Salesforce のサービス故に要約の元データとなる各種レコードへのアクセスも容易だからです。
Einstein Copilot を使うと、案件の状況確認が以下のように実施できます。*1
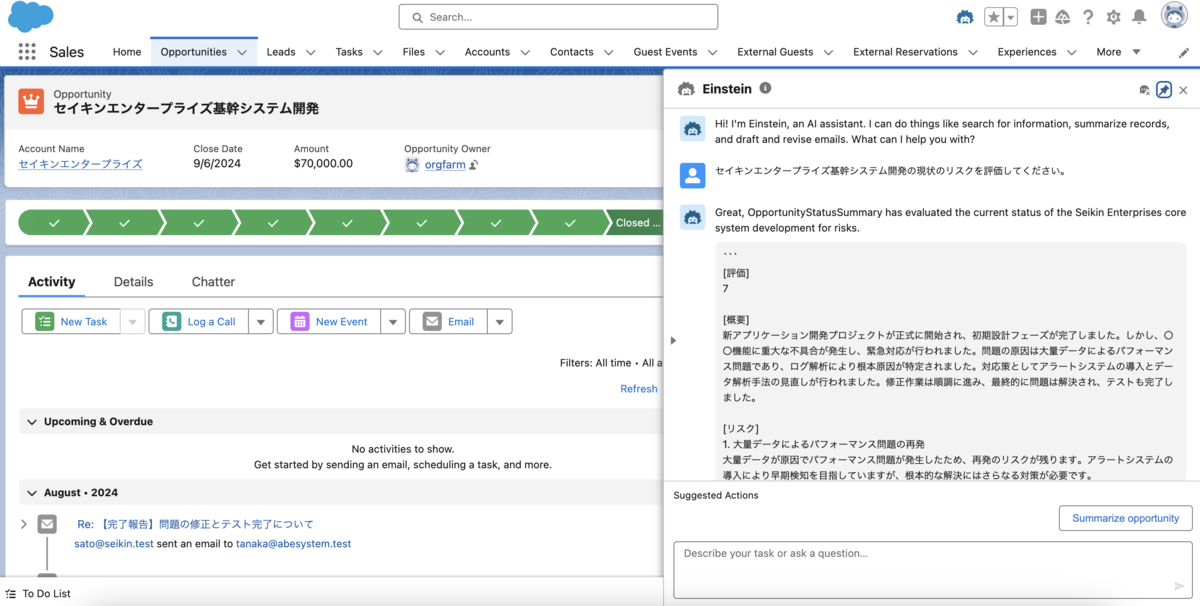
商談案件の詳細を追跡することなく、必要な情報のみを手軽に抽出できるという点がミソです。観点を指定して要約が行える LLM の強みがでていますね。
というわけで、早速実装方法の話に入っていこうと思います。
*1:画像に登場する企業名等は LLM で生成した架空のものになります。
Einstein Copilot と Data Cloud Vector Database を連携する
こんにちは。エンジニアの山下です。
今回は Einstein Copilot と Data Cloud Vector Database を連携する方法について書こうと思います。
Einstein Copilot は Salesforce が提供する LLM によるアシスタントサービスで、チャットベースで LLM に指示を行うことで、自然言語によるレコード検索やメールの文面の下書きなどを行なうことができます。地味に手間のかかる作業を LLM に一任できるため、Salesforce を普段使いする人に重宝されそうなサービスです。
Einstein Copilot の微妙な点は、デフォルトで搭載されている検索機能が CRM レコードのみを対象としており、Data Cloud のデータを検索するためには利用することができないことです。
Data Cloud に取り込んだ外部データを Einstein Copilot で扱えるようになれば、任意のデータを活用した、より柔軟な CRM 活動が行えるようになりそうな気がします。実際、そのシナジーについては Salesforce の 公式の記事 でも「最も強力な例の1つ」として紹介されているほどで、外部に活用可能なデータがある場合、連携しない理由はほとんどないと言ってもよいのではないでしょうか。
というわけで、何とか連携したいよねという話になるのですが、残念なことに、これらのサービスの連携方法についての公式情報はほとんどなく、あったとしても概ね「頑張って APEX で連携してください」という内容に留まっています。
しかし、せっかく可能性がありそうなものを放っておくのはもったいないので、本記事で具体的な連携手順を紹介し、このギャップを埋めたいと思います。
続きを読む