こんにちは,研究開発室の福井です.研究開発室においてオペレーションズ・リサーチ(OR)のビジネス活用について研究を行っております.今回は,機械学習プロジェクトを高速化するために現在研究開発室で推進している取り組みについてご紹介します.
- 機械学習プロジェクトの課題
- Databricks による課題の解決
- PoC フェーズを高速化するための Flect での取り組み
- オペレーションズ・リサーチの技術を交えたより発展的なソリューション
- 最後に
機械学習プロジェクトの課題
機械学習を実務に適用する場合,まずは業務課題と課題解決後のゴールを設定する必要があります.課題をよく議論したうえで,機械学習による課題解決が適切なアプローチであると判断された場合,次は利用可能なデータの有無の確認や分析手法の検討が必要となり,最後には実データを用いた分析やモデルの開発&学習を行っていくこととなります.
データ分析や機械学習モデルの学習を行うには,そのためのインフラが必要となります. 学習に必要なデータが比較的少数ならば,手元の 計算機 にデータをを移して jupyter notebook を用いた簡単な分析で済むかもしれませんが,大量に蓄積したセンサデータや購買データなどの大規模なデータを扱う場合はこれらのデータを効率よく取り扱うための仕組みやそれを支えるインフラが必要となります.
また,少量のデータの簡単な分析ならば jupyter notebook による書き捨てのコーディングでもあまり問題はありませんが,大規模なデータを伴う重要な課題にチームで取り組む場合は,実験設定の記録,機械学習モデルのバージョン管理,データのバージョン管理等も必要となり,それらに関連した情報をチーム内で効率よく共有する仕組みも必要となります.さらに,PoC 等のフェーズが完了した後にモデルを業務システムに組み込むためには,モデルのモニタリングやライフサイクル(再学習による更新とデプロイ)の管理も必要となります.機械学習を実務に適用するまでには,機械学習のモデル以外の様々を要素を揃える必要があります(図 1).
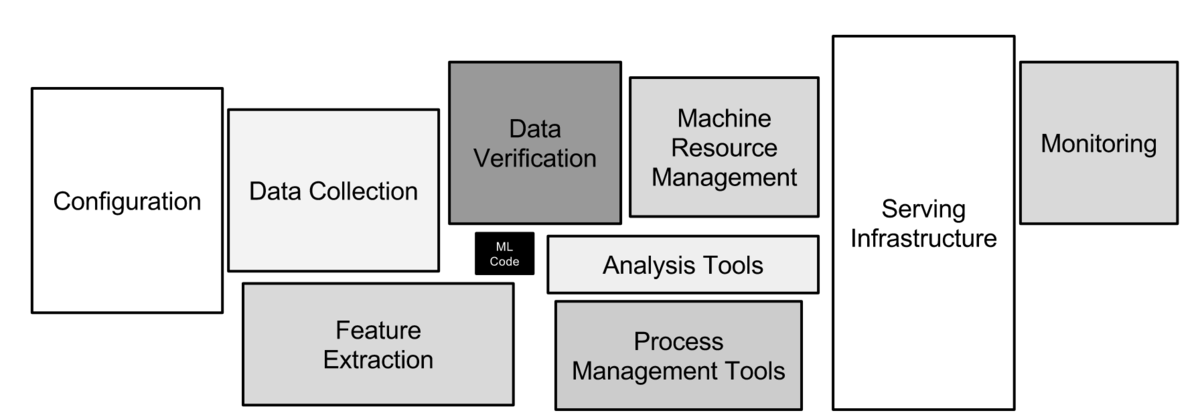
以上のように,機械学習の PoC を経てシステム化にまで至るまでには,上記のような様々な要素が必要となり,これをどのように用意するかが大きな課題の一つとなります.
Databricks による課題の解決
先述の課題に対して,Databricks の導入が有効であると考えられます.Databricks は大規模なデータの分析やそれらのデータを用いた AI 開発のためのプラットフォームであり,
- Unity Catalogによる様々なデータの一元管理
- マネージドの spark を用いた大規模なデータ処理
- マネージドの MLflow などの実験管理ツール
- 開発したモデルのサービング機能
- チームでのコラボレーションをサポートする各種の機能
- データの共有,notebook の共有,モデルの共有,実験結果の共有
- 各種リソースへの細かなアクセス権の管理
- etc.
等のデータ分析や機械学習モデルの開発,それらの運用やライフサイクルの管理も含めた MLOps において必要となる様々な機能を提供しています.特に,マネージドの spark やストリーミングデータの取り扱いを容易にしてくれる Delta Live Table がすぐに利用できる形で提供されているため,インフラ構築の手間を省力化しつつ大規模データを活用する重要な課題の方により注力しやすくなります.
このように,Databricks を導入するだけでもデータ分析や機械学習プロジェクトにおいて生じる様々な課題の助けとなることがわかります.実際に,今日では多くの企業が Databricks を導入し,このプラットフォームを様々なデータ分析や機械学習プロジェクトで活用しています.
PoC フェーズを高速化するための Flect での取り組み
Databricks を導入するだけでも様々な恩恵を受けることができますが,これに加えて Flect では Databricks が提供する Infrastructure as Code (IaC) の仕組みを活用して機械学習の PoC フェーズをスムーズに進めるための取り組みを行っています.
機械学習プロジェクトの PoC フェーズでは実データを用いて機械学習モデルの実験を行い,その性能を評価します.例えば,センサデータから機械の故障を検知することが目的であれば,センサデータを用いて機械学習モデルを学習し,そのモデルの性能を評価をこのフェーズで行います.機械学習の実問題は業務の内容に応じて多岐にわたります.
一般的には,一つ一つの実問題ごとに具体的なアプローチを検討し,そのアプローチの実装を PoC ごとに行う必要があります.しかし,特定の業種で頻繁に発生する特定の問題のみに着目すると,ある程度の事前準備が可能となります.例えば,図 2 では何らかの機械に取り付けたセンサーデータから異常検知(故障の検知)を行う流れの例を示しています.この例ではまず,生のセンサデータのデータクレンジグを行い,そこから特徴量を抽出し,その特徴量を用いて複数の異なる機械学習モデルを学習してその性能を評価するという流れを示しています.そして,評価の結果一番良かったモデルが選ばれ,そのモデルをデプロイするという流れを示しています.図 2 の例の前半のデータクレンジング処理処理までの流れ(図中の点線の左側)は実務で扱うデータの性質に応じてにどうしても変化してしまいますが,機械のセンサデータを用いた異常検知という特定の課題に限定して考えると,特徴抽出からモデルのデプロイまでの流れ(図中の点線の右側)とその実装は,他の類似した課題を扱う機械学習プロジェクトにおいても流用することが可能となるのではないかと考えられます.
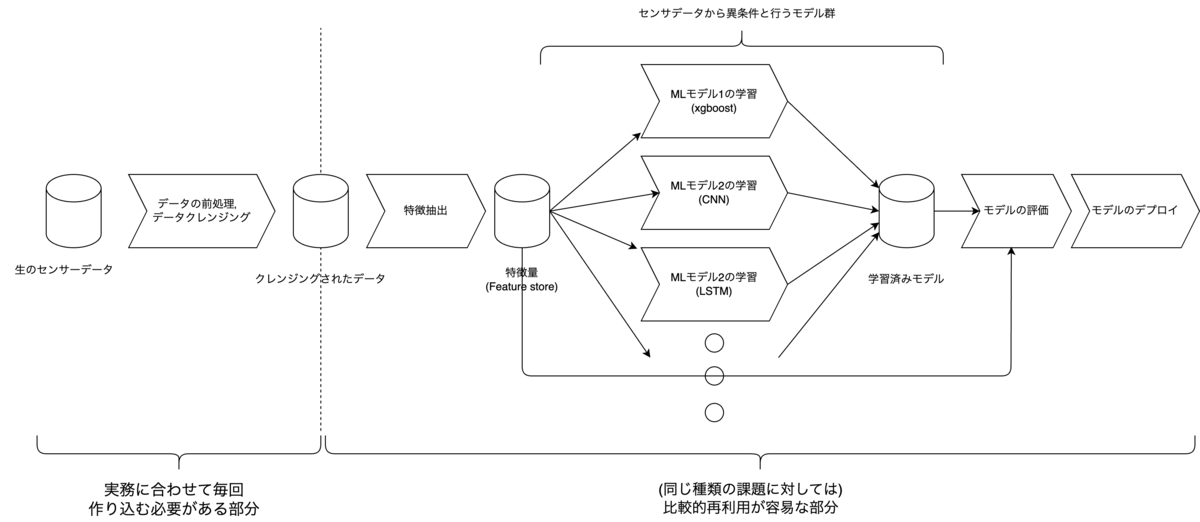
この共通化可能な処理のワークフローと機械学習モデルの実装をテンプレートとして事前に準備しておけば,類似した課題を扱う新たな機械学習プロジェクトの PoC フェーズが始まった際に必要となるのは,その実務特有のデータクレンジング処理の実装のみとなります.そして,データクレンジグ処理の実装が完了したら迅速にモデルの学習と評価に移行することが可能となります.
Databricks では,上記の図 2 のような一連のワークフローと機械学習モデルの実装を Databricks Asset Bundle (DAB)上に準備しておき,少数のコマンド実行ですぐにデプロイすることが可能です.DAB は Databricks 上に構築されるデータ処理のパイプライン,ジョブのワークフロー,機械学習モデル等のリソースを設定ファイルとして定義する IaC の仕組みであり,DAB を用いることで Databricks 上のリソースの構成を容易に再現することが可能となります.また,DAB を中心に開発を進めることで, Databricks 上のシステムを開発するチームのコラボレーションをよりスムーズにすることができます.
現在,研究開発室では先に述べたような特定の問題に対する機械学習モデル開発のワークフローを DAB の形でテンプレート化する取り組みを行っています.このテンプレートを再利用することで Databricks 上で実施される機械学習プロジェクトの PoC フェーズをよりスピーディーに進められるものと期待しています.
オペレーションズ・リサーチの技術を交えたより発展的なソリューション
ここまでに,Databricks 上でのワークフローと機械学習のモデル実装を素早く準備するためのアイデアと取り組みに関して説明をしました.ここでは,より発展的な課題解決のためのソリューションのアイデアについて述べます.
Databricks により業務に関わる何らかの予測値が得られたとしても,それをどのように活用するかはまた別の課題となります.データ分析や機械学習の技術を業務上の価値につなげるには,予測結果をもとに何らかの意思決定(具体的なアクションの決定)につなげる必要があります.しかしながら,その意思決定が困難になってしまうような状況もありえます.
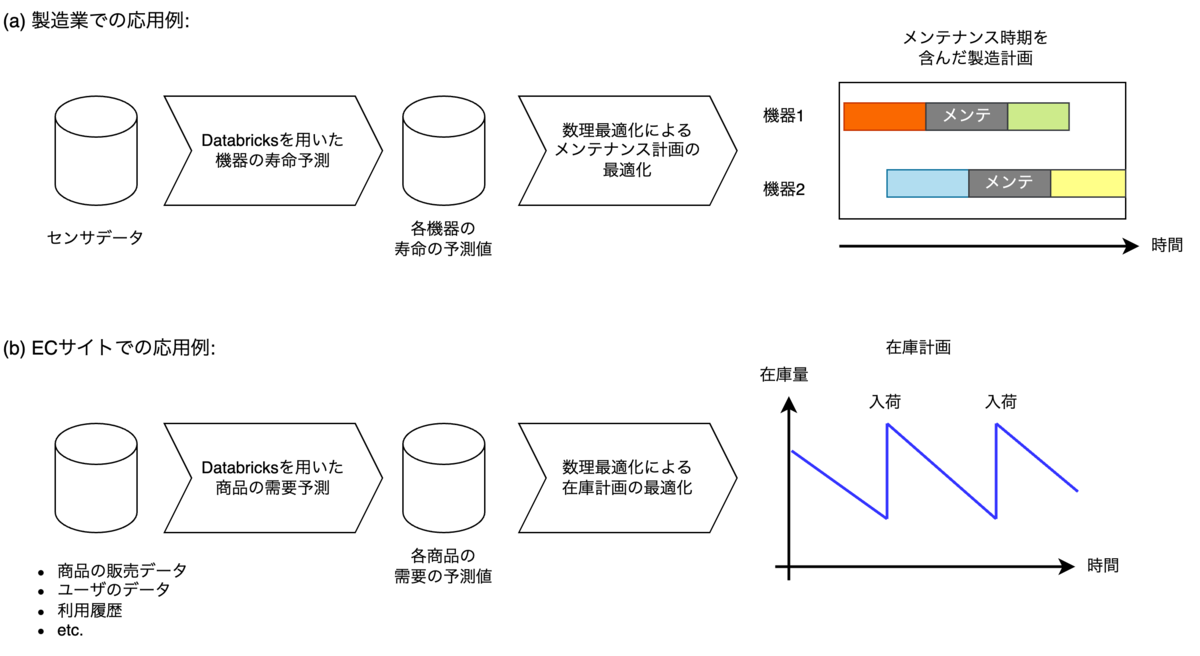
例 1: ある製造業の企業において,Industrial IoT の技術を用いてデータを収集し,そのデータを Databricks 上で分析することで各産業機械の寿命(故障時期)を予測できるようになったとします.次に,この予測結果をもとにメンテナンスのタイミングを含めた最適な製造計画を検討することになりましたが,会社が保有している機械が多く各機械が一日あたりに実施するタスクの数も膨大であるため,人力による計画の立案が非常に高負荷な作業となっていしまいます.それに加えて,「全てのラインが同時にメンテで止まらないようにしたい」などの様々な要件も含めて計画を立案しようとすると更に困難さは増します.
例 2: ある EC サイトにおいて,Databricks により顧客の購買履歴等の様々なデータを活用する機械学習モデルを構築し,その予測結果をもとに各商品の将来の需要量を予測できるようになったとします.次に,この予測結果をもとに各商品の最適な発注量を決定することとなりましたが,商品の種類が多いと在庫計画の立案が困難となってしまいます.
上記のような複雑かつ困難な意思決定/計画立案が求められる状況ではオペレーションズ・リサーチ(OR)の技術,特に OR における数理最適化の技術が有効となります.OR における数理最適化の技術を用いることで上記のような複雑な条件を踏まえた効率の良い業務計画を自動で立案することが可能となります(図 3).研究開発室では機械学習だけでなく,こうした OR の技術の研究もおこなっており,将来的には先に説明した Databricks を用いた機械学習モデル開発のソリューションだけではなく,後段の業務計画の最適化の機能も交えた研究を推進していきたいと考えています.
最後に
最後まで読んでいただきありがとうございました.Flect では今後もお客様にとって付加価値となるような新たな分野や技術に関して開拓を行っていきます. 今回紹介した機械学習関連の取り組み以外にも,業務上の意思決定に関したその他の AI や OR の研究を行っているため,もしご興味がありましたら是非ご相談ください.