こんにちは。研究開発室の東です。
今回はDatabricksを使用する際の作業領域であるワークスペースを手動で構成する方法について解説します。 本稿では、ワークスペースを構築するために必要なクラウドサービスにはAWSを使用し、S3、IAMロール、VPCなどの必要なリソースの作成にはAWS CDKを使用します。
本稿では、以下の点を取り扱います。
想定される読者は、以下のような方々です。
- Databricksの導入(premium plan以上・クラウドにAWSを使用)を考えている方
- Databricksに必要なAWSのリソースを手動で作成したい方
- CDK/ CloudformationでDatabricksに必要なクラウドリソースを一括で管理したい方
- Databricks
- ワークスペース
- ワークスペースのクイックスタートと手動作成
- Default VPCとCustomer-managed VPC
- AWS CDKを用いたリソースの作成
- ワークスペースの作成
- 最後に
Databricks
Databricksは、Databricksとクラウドサービスを連携させて、データウェアハウスとデータレイクの間で分断されている大量データの管理・分析を、シンプルなデータアーキテクチャで統合するレイクハウスプラットフォームです。 このレイクハウスプラットフォームによってデータの管理と分析のワークロードを一元化することで、データエンジニアリングからデータアナリティクス、データサイエンスまでをシームレスに行うことが特徴となります。
Databricksを利用するにあたり、まず、クラウドサービスが必要となります。使用できるクラウドサービスは、Amazon Web Services(AWS), Microsoft Azure, Google Cloudです。
以下では、クラウドサービスにAWSを使用することを前提に、Databricksのアカウントを作成後に行うワークスペースの作成の方法について解説します。
ワークスペース
Databricksでは、まずはじめにワークスペースと呼ばれる作業領域を作成します。 図1では、Databricksのアーキテクチャの構成を示しています。 図内でControl planeと呼ばれているものがワークスペースに対応しています(以後、単純にワークスペースと呼びます)。
Databricksのアーキテクチャには、Control planeとは別にClassic compute planeと呼ばれる計算リソースを配置する領域とワークスペースのメタデータを保存するためのWorkspace storage bucketが含まれます。 これらは、使用するクラウドサービスによって実体が異なりますが、AWSの場合だと
の対応関係となっています。 また、コンピュート(EC2)はユーザーのAWSアカウントで作成したVPCのプライベートサブネット内で起動されます。
そして、AWSでは、これらのリソースの管理をDatabricksのアカウント上から行うために、AWSのクロスアカウントIAMロールが必要になります。

上記からわかる通り、ワークスペースを作成し、使用するために必要なAWSリソースは、S3, VPC, IAMロールになります。冒頭で述べたように、今回はこれらのリソースをAWS CDKを使用して一括で作成し、Databricksのワークスペースとして使用するための方法について解説します。
ワークスペースのクイックスタートと手動作成
前節でCDKを使用してリソースを作成すると述べましたが、ここでは先に、ワークスペースを作成する方法について解説します。 DatabricksのUIからワークスペースを作成する際、ユーザーはワークスペースをクイックスタートで作成するか、手動で作成するかの2種類から選ぶことができます。
まずクイックスタートでは、一意なワークスペース名と使用するリージョンを選択して開始を選択すると、ユーザーのAWSアカウントのCloudformationの画面に遷移します。 その後ユーザーは特別な操作を行うことなく、Databricksから予め提供されているテンプレートを使用してCloudformationを実行するだけで、S3やIAMロールを含むCloudformationスタックが作成されます。 さらに、実行の裏側では、Classic compute planeとなるVPCが自動で作成されています。このVPCをDatabricksではDefault VPCと呼んでいます。
一方で、手動作成では文字通りにワークスペースに必要なAWSのリソースをユーザーが何かしらの方法(UI, Cloudformation, CDKなど)で手動で作成したのちに、必要情報のみをDatabricksのUIに与えてワークスペースを作成します。その際、S3とIAMロールについては特に変わりません。 しかしながら、VPCはこの場合にはCustomer-managed VPCと呼ばれており、異なっています。
違いをまとめると、以下のようになっています。
- クイックスタート
- 手動作成
ここで、なぜVPCには異なる名前がつけられているのかという点が気になると思います。 これらの違いについては、次節で解説します。
Default VPCとCustomer-managed VPC
ここでは、Default VPCとCustomer-managed VPCの違いについて解説します。 まずこれら2つの違いはリソースへのアクセス権限の違いにあります。より厳密なCustomer-managed VPCの詳細については、公式ドキュメントを参照してください。
図2では、それぞれのVPCでのアクセス権限の違いについて示しています。Default VPCでは、VPCとワークスペースが1対1の関係になりますが、Customer-managed VPCでは、VPCとワークスペースが1対多の関係で接続できます。また、後者では、同じAWSアカウント内にあるリソースへのアクセス権限についても細かく設定することができます。
これは例えば、
- 社内の情報セキュリティチームなどによってVPCの作成に関してルールが定められている場合
- Databricksアカウントを管理している部署と利用したい部署が異なっている場合
- Databricksアカウントは全社で1つだが、AWSアカウントは部署ごとに保有している場合
- お客様のAWSアカウントにあるVPCを自社Databricksアカウントのワークスペースに使用したい場合
などのケースで有用です。
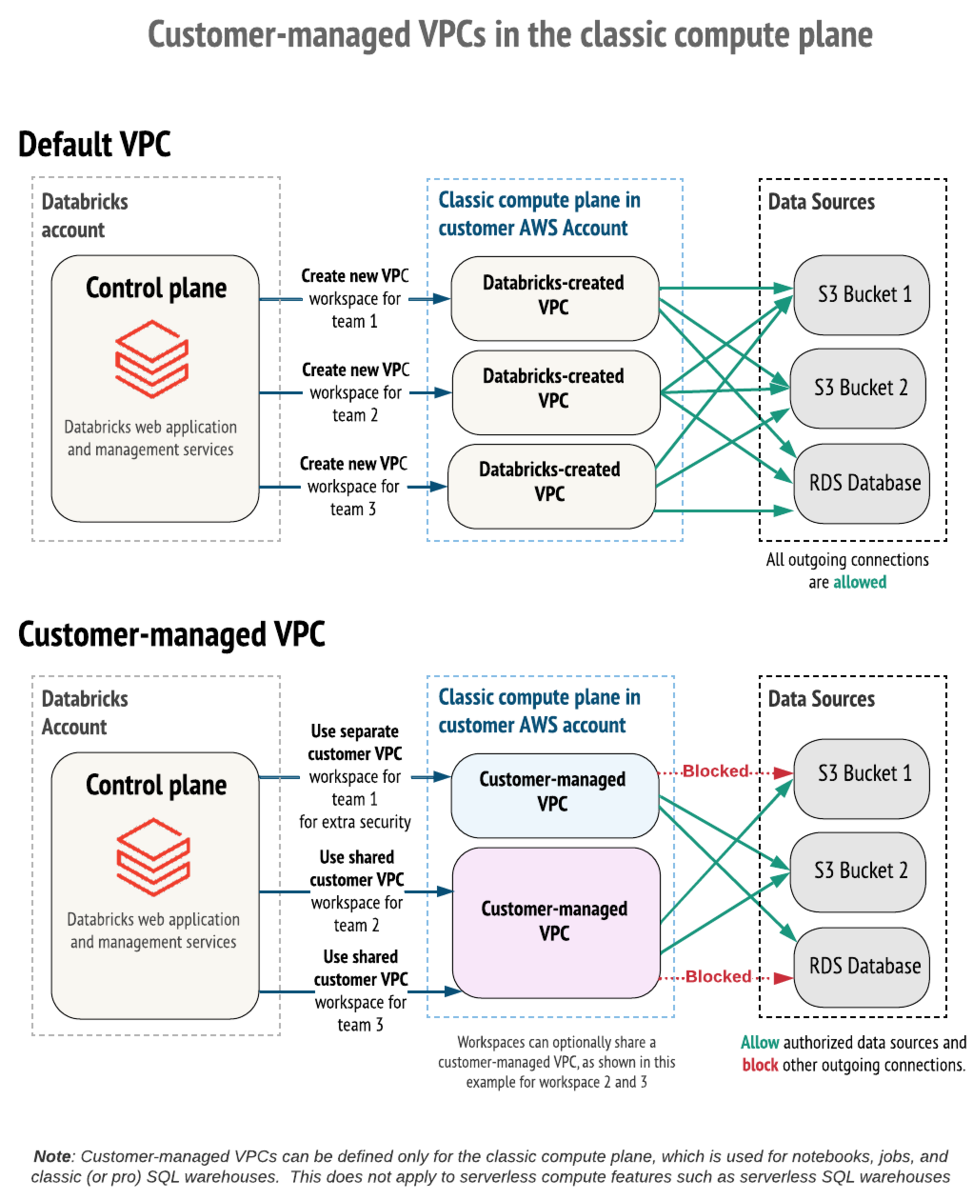
前節でも述べましたが、Default VPCはDatabricksアカウントのUIからクイックスタートを使用することで、簡単に作成できます。一方で、Customer-managed VPCはVPC内のそれぞれのリソースをユーザーが手動で設定する必要があります。しかしながら、このリソース作成手順をコードで管理し、使用する際の要件に合わせて適宜変更することで、柔軟かつ堅牢なリソース管理が可能になります。
また、CDKを使用してリソースを定義することで、定義されたリソースに対するテストコードを書いて試験することもできます(ただし、ここではテストコードについては取り扱いません)。
AWS CDKを用いたリソースの作成
AWS Cloud Development Kit (CDK)は、プログラミング言語を使用してAWSのリソースを定義し、Infrastructure as Code(IaC)を実現するためのオープンソースのソフトウェア開発フレームワークです(CDKの概要)。 TypeScript, JavaScript, Python, Java, C#, Goなどの言語に対応しています。Databricksで主に使用される言語がPythonであるため、今回はPython版のCDKを使用してリソースを定義します。
Stackクラスとパラメーターの定義
CDKでコードを記述する際に行う手続きとして、まずデプロイ可能な最小単位であるStackを定義するクラスを宣言し、その中にConstructと呼ばれるリソースの塊を定義します。 リソースを定義する際には、リソースに対して必要な情報をすべて定義することも可能ですが、デプロイ時に動的に設定するパラメーターにしておいた方が都合の良い情報もあります。
ここでは、連携するDatabricksのアカウントID、VPCのCIDRブロック、VPC内に作られるプライベートサブネットのサブネットマスク値をパラメーターとして定義しておきます。
この例では、10.0.0.0/16のアドレスを持つVPC内に、10.0.1.0/24, 10.0.2.0/24 ...のようなアドレスを持つにプライベートサブネットが自動的に作られます。
import aws_cdk as cdk import aws_cdk.aws_ec2 as ec2 import aws_cdk.aws_iam as iam import aws_cdk.aws_s3 as s3 from aws_cdk import Stack from constructs import Construct class DatabricksStack(Stack): """Stack to create S3, IAM role, and VPC for Databricks workspace.""" def __init__( self, scope: Construct, construct_id: str, **kwargs, ) -> None: super().__init__(scope, construct_id, **kwargs) # parameters account_id_param = cdk.CfnParameter( self, "AccountId", type="String", description="Your Databricks AccountID", default="aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee", ) vpc_cidr_param = cdk.CfnParameter( self, "VpcCidrBlock", type="String", description="Enter the VPC Cidr Block with /16", allowed_pattern=r"^(([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\.){3}([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])(\/16)$", default="10.0.0.0/16", ) subnet_mask_param = cdk.CfnParameter( self, "SubnetMaskBit", type="Number", description="Subnet bit 5-15 for the mask number between 17-27. The default value is 8 so that the subnet mask is /24. The NAT gateway and subnets are automatically generated following VpcCidrBlock with the specified netmask", default=8, min_value=5, max_value=15, )
クロスアカウントIAMロール
次に、Databricksのアカウントと連携するためのクロスアカウントIAMロールを作成します。ロールはメタデータをS3に保存して管理するためのカタログロールと、プログラムの実行に使用するコンピュート(実体はEC2)を作成・管理するためのワークスペースロールの2種類作成します。
カタログロール
はじめに、カタログロールのサンプルコードを示します。このサンプルでは、後ほど説明するS3バケットに対してGetやPut、Listなどの必要なポリシーを設定しています。
サンプル内の
"arn:aws:iam::414351767826:role/unity-catalog-prod-UCMasterRole-14S5ZJVKOTYTL"は、Databricksが保有するアカウント内のロールなので、変更しないように注意してください。
databricksCatalogIamRole = iam.CfnRole(
self,
"DatabricksCatalogIAMRole",
assume_role_policy_document={
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::414351767826:role/unity-catalog-prod-UCMasterRole-14S5ZJVKOTYTL",
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": f"""{account_id_param.value_as_string}""",
},
},
},
{
"Effect": "Allow",
"Principal": {
"AWS": f"""arn:aws:iam::{self.account}:root""",
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"AWS:PrincipalArn": f"""arn:aws:iam::{self.account}:role/databricks-workspace-{self.stack_name}-catalog-role""",
"sts:ExternalId": f"""{account_id_param.value_as_string}""",
},
},
},
],
},
policies=[
{
"policyName": f"""databricks-workspace-{self.stack_name}-catalog-policy""",
"policyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:GetLifecycleConfiguration",
"s3:PutLifecycleConfiguration",
],
"Resource": [
f"""arn:aws:s3:::databricks-workspace-{self.stack_name}-bucket/*""",
f"""arn:aws:s3:::databricks-workspace-{self.stack_name}-bucket""",
],
},
{
"Effect": "Allow",
"Action": [
"sts:AssumeRole",
],
"Resource": [
f"""arn:aws:iam::{self.account}:role/databricks-workspace-{self.stack_name}-role""",
],
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcL",
],
"Resource": [
f"""arn:aws:s3:::databricks-workspace-{self.stack_name}-bucket/*""",
f"""arn:aws:s3:::databricks-workspace-{self.stack_name}-bucket""",
],
"Condition": {
"StringLike": {
"s3:x-amz-acl": "bucket-owner-full-control",
},
},
},
],
},
},
],
role_name=f"""databricks-workspace-{self.stack_name}-catalog-grole""",
)
ワークスペースロール
次に、ワークスペースロールのサンプルを示します。このロールはassume roleを通して、Databricksが保有するAWSアカウントにEC2を管理する権限を付与しています。
サンプル内の
arn:aws:iam::414351767826:rootはDatabricksが保有するアカウントのarnなので、変更しないように注意してください。
databricksWorkspaceIamRole = iam.CfnRole(
self,
"DatabricksWorkspaceIAMRole",
assume_role_policy_document={
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "ec2.amazonaws.com",
},
"Action": "sts:AssumeRole",
},
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::414351767826:root",
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": f"""{account_id_param.value_as_string}""",
},
},
},
],
},
policies=[
{
"policyName": f"""databricks-workspace-{self.stack_name}-workspace-policy""",
"policyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1403287045000",
"Effect": "Allow",
"Action": [
"ec2:AssociateIamInstanceProfile",
"ec2:AttachVolume",
"ec2:AuthorizeSecurityGroupEgress",
"ec2:AuthorizeSecurityGroupIngress",
"ec2:CancelSpotInstanceRequests",
"ec2:CreateTags",
"ec2:CreateVolume",
"ec2:DeleteTags",
"ec2:DeleteVolume",
"ec2:DescribeAvailabilityZones",
"ec2:DescribeIamInstanceProfileAssociations",
"ec2:DescribeInstanceStatus",
"ec2:DescribeInstances",
"ec2:DescribeInternetGateways",
"ec2:DescribeNatGateways",
"ec2:DescribeNetworkAcls",
"ec2:DescribePrefixLists",
"ec2:DescribeReservedInstancesOfferings",
"ec2:DescribeRouteTables",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSpotInstanceRequests",
"ec2:DescribeSpotPriceHistory",
"ec2:DescribeSubnets",
"ec2:DescribeVolumes",
"ec2:DescribeVpcAttribute",
"ec2:DescribeVpcs",
"ec2:DetachVolume",
"ec2:DisassociateIamInstanceProfile",
"ec2:ReplaceIamInstanceProfileAssociation",
"ec2:RequestSpotInstances",
"ec2:RevokeSecurityGroupEgress",
"ec2:RevokeSecurityGroupIngress",
"ec2:RunInstances",
"ec2:TerminateInstances",
"ec2:DescribeFleetHistory",
"ec2:ModifyFleet",
"ec2:DeleteFleets",
"ec2:DescribeFleetInstances",
"ec2:DescribeFleets",
"ec2:CreateFleet",
"ec2:DeleteLaunchTemplate",
"ec2:GetLaunchTemplateData",
"ec2:CreateLaunchTemplate",
"ec2:DescribeLaunchTemplates",
"ec2:DescribeLaunchTemplateVersions",
"ec2:ModifyLaunchTemplate",
"ec2:DeleteLaunchTemplateVersions",
"ec2:CreateLaunchTemplateVersion",
"ec2:AssignPrivateIpAddresses",
"ec2:GetSpotPlacementScores",
],
"Resource": [
"*",
],
},
{
"Effect": "Allow",
"Action": [
"iam:CreateServiceLinkedRole",
"iam:PutRolePolicy",
],
"Resource": [
"arn:aws:iam::*:role/aws-service-role/spot.amazonaws.com/AWSServiceRoleForEC2Spot",
],
"Condition": {
"StringLike": {
"iam:AWSServiceName": "spot.amazonaws.com",
},
},
},
],
},
},
],
role_name=f"""databricks-workspace-{self.stack_name}-workspace-role""",
)
S3バケット
Databricksワークスペースのメタデータを保存・管理するためのS3バケットと、そのバケットのポリシーを定義します。
まずはじめに、バケットを作成します。このとき、バケットのバージョニングとパブリックアクセスの拒否は有効にしておきます。
databricksS3Bucket = s3.CfnBucket(
self,
"DatabricksS3Bucket",
bucket_name=f"""databricks-workspace-{self.stack_name}-bucket""",
versioning_configuration={
"status": "Enabled",
},
public_access_block_configuration={
"blockPublicAcls": True,
"blockPublicPolicy": True,
"ignorePublicAcls": True,
"restrictPublicBuckets": True,
},
tags=[
{
"key": "Name",
"value": f"""{self.stack_name}-DatabricksWorkspaceBucket""",
},
],
)
バケットポリシー
次に、このバケットに付与するためのポリシーを定義します。まず、Databricksの保有するAWSのアカウントに、このバケットに対してのGet, Put, Delete, Listなどの操作を許可する権限を付与します。
その後、同アカウントにこのバケットのunity-catalogフォルダー以下のオブジェクトに対するすべての操作を拒否する設定を付与します。
このunity-catalogフォルダーには、データテーブルや機械学習のモデルなどのデータが含まれています。Unity Catalogに関しての詳細はDatabricksによるUnityCatalogの説明を参照してください。
databricksS3BucketPolicy = s3.CfnBucketPolicy(
self,
"DatabricksS3BucketPolicy",
bucket=databricksS3Bucket.ref,
policy_document={
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Grant Databricks Access",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::414351767826:root",
},
"Action": [
"s3:GetObject",
"s3:GetObjectVersion",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket",
"s3:GetBucketLocation",
],
"Resource": [
f"""arn:aws:s3:::databricks-workspace-{self.stack_name}-bucket/*""",
f"""arn:aws:s3:::databricks-workspace-{self.stack_name}-bucket""",
],
"Condition": {
"StringEquals": {
"aws:PrincipalTag/DatabricksAccountId": f"""{account_id_param.value_as_string}""",
},
},
},
{
"Sid": "Prevent DBFS from accessing Unity Catalog metastore",
"Effect": "Deny",
"Principal": {
"AWS": "arn:aws:iam::414351767826:root",
},
"Action": "s3:*",
"Resource": f"""arn:aws:s3:::databricks-workspace-{self.stack_name}-bucket/unity-catalog/*""",
},
],
},
)
VPC
VPCとその内部のサブネットやルートテーブル、VPCエンドポイントを作成します。 このサンプルで最終的に作成されるVPCのリソースマップは図3のようになります。

以後、VPCの構築について説明していきますが、まずDatabricksのワークスペースに使用できるVPCには要件が定められており、以下となっています(個々のリソースの要件は後ほど紹介します)。
AWSのリージョン
異なるAvailability Zone(AZ)にある2つ以上のプライベートサブネット
- サブネットはNATゲートウェイなどでパブリックネットワークへアクセスできる必要があります。
セキュリティグループ
VPCの作成
VPCを作成します。本稿では、リージョンはus-west-2を仮定しています。
DNSホスト名とDNS解決を有効化したVPCのサンプルは次のようになります。アドレスには、パラメーターによって設定された値が使用されます(デフォルトでは、10.0.0.0/16)。
vpc = ec2.CfnVPC(
self,
"VPC",
cidr_block=f"""{vpc_cidr_param.value_as_string}""",
enable_dns_hostnames=True,
enable_dns_support=True,
tags=[
{
"key": "Name",
"value": f"""databricks-workspace-{self.stack_name}-vpc""",
},
],
)
NATゲートウェイ・インターネットゲートウェイ
プライベートサブネットをパブリックネットワークにアクセス可能にするために、NATゲートウェイを作成します。NATゲートウェイサブネットにはVPCのアドレスとパラメーターによって設定されたマスク値を使用したアドレスが割り当てられます。また、AZは使用可能なものから最初のもの(例えば、us-west-2aなど)が使用されます。
同時にインターネットゲートウェイを作成しておきます。
# Internet gateway internetGateway = ec2.CfnInternetGateway( self, "InternetGateway", ) # NAT gateway EIP natGatewayEip = ec2.CfnEIP( self, "NATGatewayEIP", domain="vpc", ) # NAT gateway subnet natGatewaySubnet = ec2.CfnSubnet( self, "NATGatewaySubnet", vpc_id=vpc.ref, availability_zone=cdk.Fn.select(0, cdk.Fn.get_azs("")), cidr_block=cdk.Fn.select( 0, cdk.Fn.cidr( vpc.attr_cidr_block, 1, str(subnet_mask_param.value_as_string) ), ), map_public_ip_on_launch=True, ) # NAT gateway natGateway = ec2.CfnNatGateway( self, "NATGateway", allocation_id=natGatewayEip.attr_allocation_id, subnet_id=natGatewaySubnet.ref, )
サブネットの作成
サブネットを作成します。今オレゴン(us-west-2)のリージョンを仮定していますが、オレゴンには4つのAZがあるので4つ作成します。この部分や後ほど説明するルーティングは、使用するAZに合わせて適宜変更してください。
それぞれのサブネットのアドレスは、VPCのアドレスとパラメーターのサブネットのマスク値を参照して自動的に決定します。例えば、VPCのアドレスが10.0.0.0/16の場合、サブネットのアドレスは10.0.1.0/24, 10.0.2.0/24 ...のようになります。
# private subnet 1 subnet1 = ec2.CfnSubnet( self, "Subnet1", vpc_id=vpc.ref, availability_zone=cdk.Fn.select(0, cdk.Fn.get_azs("")), cidr_block=cdk.Fn.select( 1, cdk.Fn.cidr( vpc.attr_cidr_block, 2, str(subnet_mask_param.value_as_string) ), ), ) # private subnet 2 subnet2 = ec2.CfnSubnet( self, "Subnet2", vpc_id=vpc.ref, availability_zone=cdk.Fn.select(1, cdk.Fn.get_azs("")), cidr_block=cdk.Fn.select( 2, cdk.Fn.cidr( vpc.attr_cidr_block, 3, str(subnet_mask_param.value_as_string) ), ), ) # private subnet 3 subnet3 = ec2.CfnSubnet( self, "Subnet3", vpc_id=vpc.ref, availability_zone=cdk.Fn.select(2, cdk.Fn.get_azs("")), cidr_block=cdk.Fn.select( 3, cdk.Fn.cidr( vpc.attr_cidr_block, 4, str(subnet_mask_param.value_as_string) ), ), ) # private subnet 4 subnet4 = ec2.CfnSubnet( self, "Subnet4", vpc_id=vpc.ref, availability_zone=cdk.Fn.select(3, cdk.Fn.get_azs("")), cidr_block=cdk.Fn.select( 4, cdk.Fn.cidr( vpc.attr_cidr_block, 5, str(subnet_mask_param.value_as_string) ), ), )
ルーティング
サブネットを関連付けるためのテーブルを作成し、その後、ゲートウェイにルーティングします。この時、0.0.0.0/0へのトラフィックを使用します。
テーブルはパブリックのものと、プライベートのものを両方作成します。
# Private route table privateRouteTable = ec2.CfnRouteTable( self, "PrivateRouteTable", vpc_id=vpc.ref, ) # Public route table publicRouteTable = ec2.CfnRouteTable( self, "PublicRouteTable", vpc_id=vpc.ref, )
次に、それぞれのテーブルのルーティングと、インターネットゲートウェイのVPCへのアタッチを行います。
# Attach gateway vpcGatewayAttachment = ec2.CfnVPCGatewayAttachment( self, "VPCGatewayAttachment", vpc_id=vpc.ref, internet_gateway_id=internetGateway.ref, ) # NAT gateway subnet route table association natGatewaySubnetRouteTableAssociation = ec2.CfnSubnetRouteTableAssociation( self, "NATGatewaySubnetRouteTableAssociation", subnet_id=natGatewaySubnet.ref, route_table_id=publicRouteTable.ref, ) # Public route publicRoute = ec2.CfnRoute( self, "PublicRoute", route_table_id=publicRouteTable.ref, destination_cidr_block="0.0.0.0/0", gateway_id=internetGateway.ref, ) # Private Route privateRoute = ec2.CfnRoute( self, "PrivateRoute", route_table_id=privateRouteTable.ref, destination_cidr_block="0.0.0.0/0", nat_gateway_id=natGateway.ref, )
そして、それぞれのプライベートサブネットをルートテーブルに関連付けます。
# Associate subnets to route table subnet1RouteTableAssociation = ec2.CfnSubnetRouteTableAssociation( self, "Subnet1RouteTableAssociation", subnet_id=subnet1.ref, route_table_id=privateRouteTable.ref, ) subnet2RouteTableAssociation = ec2.CfnSubnetRouteTableAssociation( self, "Subnet2RouteTableAssociation", subnet_id=subnet2.ref, route_table_id=privateRouteTable.ref, ) subnet3RouteTableAssociation = ec2.CfnSubnetRouteTableAssociation( self, "Subnet3RouteTableAssociation", subnet_id=subnet3.ref, route_table_id=privateRouteTable.ref, ) subnet4RouteTableAssociation = ec2.CfnSubnetRouteTableAssociation( self, "Subnet4RouteTableAssociation", subnet_id=subnet4.ref, route_table_id=privateRouteTable.ref, )
セキュリティグループ
最後にセキュリティグループの設定を行います。既存のセキュリティグループを再利用することも可能ですが、Databricksでは1つのワークスペースに対して一意のサブネットとセキュリティグループを使用することが推奨されていますので、新しくセキュリティグループを作成します。
セキュリティグループの要件は以下のようになっています *1 。
アウトバウンド
インバウンド
上記を踏まえたセキュリティグループの作成サンプルは以下のようになります。
# Security group securityGroup = ec2.CfnSecurityGroup( self, "SecurityGroup", group_description="Databricks Security Group", vpc_id=vpc.ref, security_group_egress=[ { "ipProtocol": "-1", "cidrIp": "0.0.0.0/0", }, { "ipProtocol": "tcp", "fromPort": 443, "toPort": 443, "cidrIp": "0.0.0.0/0", }, { "ipProtocol": "tcp", "fromPort": 3306, "toPort": 3306, "cidrIp": "0.0.0.0/0", }, { "ipProtocol": "tcp", "fromPort": 8443, "toPort": 8443, "cidrIp": "0.0.0.0/0", }, { "ipProtocol": "tcp", "fromPort": 8444, "toPort": 8444, "cidrIp": "0.0.0.0/0", }, { "ipProtocol": "tcp", "fromPort": 8445, "toPort": 8451, "cidrIp": "0.0.0.0/0", }, ], tags=[ { "key": "Name", "value": f"""databricks-workspace-{self.stack_name}-security-group""", }, ], ) # Security Group for Tcp ingress securityGroupDefaultTcpIngress = ec2.CfnSecurityGroupIngress( self, "SecurityGroupDefaultTcpIngress", group_id=securityGroup.attr_group_id, description="Allow all tcp inbound access from the same security group", source_security_group_id=securityGroup.attr_group_id, ip_protocol="tcp", from_port=0, to_port=65535, ) # Security Group for Udp ingress securityGroupDefaultUdpIngress = ec2.CfnSecurityGroupIngress( self, "SecurityGroupDefaultUdpIngress", group_id=securityGroup.attr_group_id, description="Allow all udp inbound access from the same security group", source_security_group_id=securityGroup.attr_group_id, ip_protocol="udp", from_port=0, to_port=65535, )
S3 エンドポイント (オプション)
ここまでで、必要なリソースの作成が終了しました。他方で、Customer-managed VPCを使用する場合、DatabricksではAWSサービスへのリージョンVPCエンドポイントのみを使用するようにVPCを構成することが推奨されています。詳細は公式ドキュメントを参照してください。
ここでは、同一リージョン用のS3VPCエンドポイントを作成します。
vpcEndpointS3 = ec2.CfnVPCEndpoint(
self,
"VPCEndpointS3",
vpc_id=vpc.ref,
service_name=f"""com.amazonaws.{self.region}.s3""",
route_table_ids=[
privateRouteTable.ref,
],
)
出力
ここで、作成したリソースの情報のなかから、Databricksのワークスペースの作成に必要なものを出力するように設定しましょう。 出力しておくことで、ワークスペース作成時に、必要な情報をひとまとめに見ることができます。
ワークスペースの作成時に必要な情報は以下のものです。
- 2つのロールそれぞれのARN
- メタデータ保存用のS3バケットの名前
- VPCのID (vpc-xxx)
- セキュリティグループのID (sg-xxx)
- それぞれのサブネットのID (subnet-xxx)
これらを出力するためのサンプルは次のようになります。
# Outputs # VPC ID self.vpc_id = vpc.ref cdk.CfnOutput( self, "CfnOutputVPCId", key="VPCId", description="VPC ID", value=str(self.vpc_id), ) # Private Subnet 1 ID self.public_subnet1_id = subnet1.ref cdk.CfnOutput( self, "CfnOutputPrivateSubnet1Id", key="PrivateSubnet1Id", description="Private Subnet 1 ID", value=str(self.public_subnet1_id), ) # Private Subnet 2 ID self.public_subnet2_id = subnet2.ref cdk.CfnOutput( self, "CfnOutputPrivateSubnet2Id", key="PrivateSubnet2Id", description="Private Subnet 2 ID", value=str(self.public_subnet2_id), ) # Private Subnet 3 ID self.public_subnet3_id = subnet3.ref cdk.CfnOutput( self, "CfnOutputPrivateSubnet3Id", key="PrivateSubnet3Id", description="Private Subnet 3 ID", value=str(self.public_subnet3_id), ) # Private Subnet 4 ID self.public_subnet4_id = subnet4.ref cdk.CfnOutput( self, "CfnOutputPrivateSubnet4Id", key="PrivateSubnet4Id", description="Private Subnet 4 ID", value=str(self.public_subnet4_id), ) # Security Group ID self.security_group_id = securityGroup.ref cdk.CfnOutput( self, "CfnOutputSecurityGroupId", key="SecurityGroupId", description="Security Group ID", value=str(self.security_group_id), ) # S3 Bucket Name self.s3_bucket_name = databricksS3Bucket.ref cdk.CfnOutput( self, "CfnOutputS3BucketName", key="S3BucketName", description="S3 Bucket Name", value=str(self.s3_bucket_name), ) # Workspace IAM Role ARN self.workspace_iam_role_arn = databricksWorkspaceIamRole.attr_arn cdk.CfnOutput( self, "CfnOutputWorkspaceIAMRoleArn", key="WorkspaceIAMRoleArn", description="Workspace IAM Role ARN", value=str(self.workspace_iam_role_arn), ) # Catalog IAM Role ARN self.catalog_iam_role_arn = databricksCatalogIamRole.attr_arn cdk.CfnOutput( self, "CfnOutputCatalogIAMRoleArn", key="CatalogIAMRoleArn", description="Catalog IAM Role ARN", value=str(self.catalog_iam_role_arn), )
ここまでで作成したクラスを使用してCloudformationのスタックをデプロイするとワークスペースの作成に必要なAWSのリソースを一括で作成・管理することができます。
デプロイ後のCloudformationのスタックは以下の図4のようになっています。

ワークスペースの作成
では、ここまでで作成したスタックのリソースを使用して、ワークスペースを手動で作成してみましょう。
まず、Databricksのアカウントコンソールにログインし、ワークスペースタブからワークスペースの作成→手動を選択します。
1. ワークスペース名とリージョンの設定
次の図5のような画面に任意のワークスペース名とリージョン(サンプルではus-west-2)を入力します。

2. ストレージの設定
図6のような画面に任意のストレージの資格の名前とS3のバケット名、カタログロールのARNを入力します。

3. ワークスペース資格の設定
図7のような画面に任意のワークスペース用の資格の名前と、ワークスペースロールのARNを入力します。

4. VPCの設定
図8のような画面のAdvanced Configurationタブを押し、Network configurationからAdd a new network configurationを選択します。

このような画面(図9)が出てくるので、作成したVPC, サブネット、セキュリティグループのIDをすべて入力します。

入力が完了して、次の画面(図10)に遷移する際にエラーがでなければそのまま作成して終了となります。

最後に
ここまでお読みいただきありがとうございました。今回はAWS CDKを使用して、Customer-managed VPCを含む、Databricksのワークスペースを作成するために必要なリソースを一括で作成する方法と、それからワークスペースを手動で作成する方法について解説いたしました。
Flectでは今後もお客様にとって付加価値となるような新たな分野や技術に関して開拓を行っていきます。 今回紹介したのもの以外にも様々な研究・開発を行っています。 もしご興味がありましたら是非ご相談ください。
また、先日公開した記事では、現在研究開発室が推進している「Databricks を活用した機械学習プロジェクトに対するの取り組み」を紹介しています (https://cloud.flect.co.jp/entry/2024/09/30/180553)。 こちらも本稿と合わせてご一読いただけると幸いです。
*1:今回はpremium planを使用しているので6666と2443は使用しません。enterprise planの場合は、プライベートリンクやコンプライアンスセキュリティプロファイルを使用するために、これらのポートを解放します。詳細はプライベートリンクやコンプライアンスセキュリティプロファイルを参照してください。