こんにちは。エンジニアの山下です。
前回の記事 で Einstein Discovery と Einstein Next Best Action の連携方法の一例として、Einstein Discovery の推論結果を元に Einstein Next Best Action のレコメンデーションの出し分けを行う方法を紹介しました。
今回はもう少し進んだ例として、Einstein Discovery で行ったマッチング処理の結果を Einstein Next Best Action のレコメンデーションとして表示する方法について書こうと思います。
やりたいこと
今回は Salesforce の標準オブジェクトの Contact 同士の相性診断を行い、Contact のレコードページでマッチングスコア上位3つまでをレコメンデーションとして表示したいと思います。レコメンデーションの説明文には対応する Contact の名前と ID を表示しておき、レコメンデーションを承諾した場合には Contact ID を元にした何らかの処理を行うということにしておきます。
イメージは以下のような感じです:

コミュニケーション促進用途を想定してそれっぽくしてみました。
あとは背後で動く仕組みをどうするかですが、以下のような構成でいきます。
- Einstein Discovery でマッチングスコア算出のためのモデルを構築
- CRM Analytics Data Prep で Contact の全ペアのマッチングスコアを算出
- マッチングスコアから Einstein Next Best Action のレコメンデーションを作成
最大の難所は Einstein Next Best Action が絡むステップで、ここでは今回のユースケースに合わせて Einstein Next Best Action の制約を回避する作業が必要になります。詳細は後述します。
では上から順にポイントを説明していきます。
Einstein Discovery でモデルを構築する
まずはマッチングスコア算出用のモデルの準備からです。モデルの構築にあたって入力用のデータが必要なため、適当なスクリプトから生成するなどして準備しておきます。
参考までに今回は以下の Python スクリプトでデータを生成しました。
import csv import random import uuid AGE_MIN = 20 AGE_MAX = 60 SCORE_NOISE_MAX = 5.0 SCORE_NOISE_MIN = -5.0 NUM_OF_DATA = 1000 if __name__ == '__main__': with open('out.csv', 'w') as f: fieldnames = ['id', 'age1', 'age2', 'score'] writer = csv.DictWriter(f, fieldnames=fieldnames, dialect='unix') writer.writeheader() for i in range(NUM_OF_DATA): id = uuid.uuid4().hex age1 = random.randint(AGE_MIN, AGE_MAX) age2 = random.randint(AGE_MIN, AGE_MAX) # high score if they are around same age noise = random.uniform(SCORE_NOISE_MIN, SCORE_NOISE_MAX) score = (AGE_MAX - AGE_MIN) - abs(age1 - age2) + noise writer.writerow({'id': id, 'age1': age1, 'age2': age2, 'score': score})
Contact のペアのそれぞれの年齢を受け取り、年齢が近いほど高いスコアを出力するという、極めて前時代的なアルゴリズムを使用しています。適当にアレンジして使用してください。
データさえあれば Einstein Discovery のモデル構築は非常に容易で、Trailhead を一読すれば簡単に実施することができます。
注意事項として、モデルをデプロイする際に「モデルを Salesforce オブジェクトに接続する/しない」という選択肢が表示されますが、これは「接続しない」を選択します。「接続する」を選択した場合、単一レコードのフィールドからしかモデルの入力パラメータを設定できないという制約が課されるのですが、今回は複数(2つ)の Contact レコードからモデルに入力を行う必要があるため、この制約を受け入れることはできません。
CRM Analytics でマッチングスコアを算出する
作成した Einstein Discovery のモデルを CRM Analytics の Data Prep Recipe から呼び出してマッチングスコアの算出を行います。Data Prep Recipe についても特に難しい点はなく、こちら の公式ドキュメントを参考にすれば簡単に作成できます。
Recipe の中で実施する内容は、
- Contact 同士の Cross Join をとる
- 1 で得た結果から同じ Contact 同士の組合せを取り除く
- 2 で得た結果に対して Einstein Discovery モデルの推論を適用する
- 3 で得た結果を Dataset として保存する
という感じです。
3 で CRM Analytics と Einstein Discovery を連携させることになりますが、これも設定上は特に難しい点はなく、Recipe のパイプライン上に Discovery Predict ブロックを追加して入力パラメータを設定するだけで連携できます。
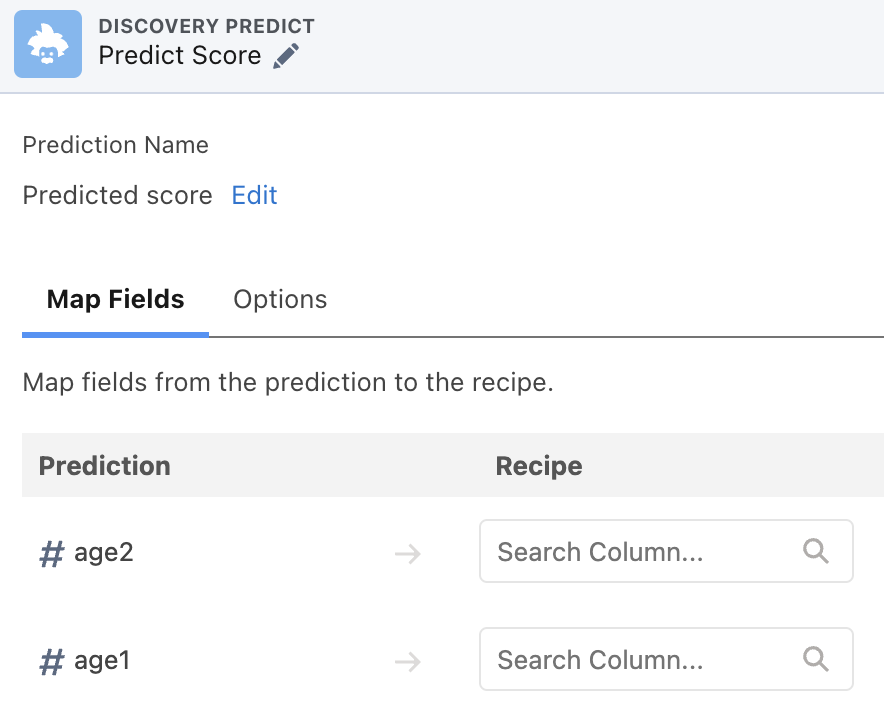
参考までに筆者が作成した Recipe のパイプラインが以下です:

Predict Score の後に Transform ブロックが1つ入っていますが、このブロックでは API 名の調整をしています。特に Cross Join を行った際に Join 元のカラムの API 名が partner.Id のように . を含む名前に変更されますが、後ほど APEX から Dataset を参照する際に . があると煩雑な対応が必要になるため、ここで修正しています。
Recipe の作成後は実行して Dataset を生成しておきます。
Einstein Next Best Action のレコメンデーションを作成する
いよいよ本丸です。冒頭でも述べましたが、ここが最大の難所です。
何がそれほど難しいのかというと、Einstein Next Best Action に非常に拡張性の乏しい仕様になっている箇所があり、それを回避するのが難しいです。クラウドサービスに携わっている以上、仕様上の制約にはそれなりの頻度で遭遇しますが、Einstein Next Best Action の制約は結構深刻で、ユースケースによっては簡単に詰むくらいのインパクトがあります。
具体的には、今回のユースケースでは以下の2つの仕様上の制約を回避する必要があります。
レコメンデーションの説明文に動的な文章を設定できない
レコメンデーションの説明文に設定できるのは固定の文章のみという制約があります。これは説明文にマッチングスコア上位のお相手の Contact の情報を掲載する際に障害となります。
しかし、レコメンデーション自体を APEX から動的に生成することでこの制約は回避でき、次に紹介する制約に比べれば些事に思える内容です。
レコメンデーション承諾時に起動する Flow から起動元のレコメンデーションの情報を入手する手段がない
何を言っているのかわからないかもしれませんが、私も同じ気持ちです。どうしてこうなった ... 。
残念ながら、レコメンデーションが承諾された際に起動する Flow から、起動元となるレコメンデーションに関する情報を得る手段はありません。では何の情報なら得られるかというと、実は基本的に何の情報も得られません。公式ドキュメントを精査した限りでは、起動されたという事実だけを元に素材ゼロから処理をするというのが Einstein Next Best Action の基本です。
公式ドキュメントに記載のある唯一の例外は isRecommendationAccepted という変数で、この変数にはレコメンデーションが承諾されたか拒否されたかの情報が真偽値で格納されます。しかし、この情報だけで今回のユースケースを実現するのは当然不可能です。
詰んだ ... かと思いましたが、色々調べた結果、以下のスレッドに突破口となる情報が記載されているのを発見しました。
上記のスレッドには Einstein Next Best Action に recordId という隠しパラメータが存在し、それを使えばレコメンデーションが表示されている対象の Contact の ID が得られるという旨が記載されています。なぜ隠した。
残念ながらレコメンデーション自体の情報はやはり得られませんが、これを使って実装を工夫すれば、レコメンデーションに対応する Contact のペアの両方の ID を取得することが可能となります。
具体的には、レコメンデーション承諾時の Flow を3つ定義し、それぞれをマッチングスコア1位のレコメンデーションのための Flow・2位のための Flow というように定めます。これにより、どの Flow が起動したかによってマッチングスコアの順位が特定できます。さらに特定した順位と recordId を組み合わせることで、どの Contact の何位のお相手かが特定できるという寸法です。
図にすると以下のようになります:

これで全ての制約が回避できる見通しがつきました。というわけで、具体的な実装方法に進みます。
レコメンデーション承諾時の Flow を作成する
先述の通り、3つの Flow を作成します。が、その前に recordId とマッチングスコア順位からお相手の Contact ID を取得するための APEX Action を定義しておきます。
APEX から CRM Analytics API を利用するには Wave という名前空間にあるクラス群を利用します。Dataset へのクエリについては こちら の公式ドキュメントにあるサンプルコードを一読するのがオススメです。
global class GetPartnerId { private static String DATASET_ID = '(your-dataset-id)'; // NOTE: 固定値ではなく REST API 経由で適宜 currentVersionId を取得するのが理想だが今回は割愛 private static String DATASET_VERSION_ID = '(your-dataset-version-id)'; @InvocableMethod public static List<String> get(List<Input> inputs) { String id = inputs[0].id; Integer targetIndex = inputs[0].targetIndex; List<Record> records = retrieveScores(id); records.sort(new ScoreComparator()); Record target = records[targetIndex]; return new List<String>{target.partnerId}; } private static List<Record> retrieveScores(String id) { Wave.ProjectionNode[] projs = new Wave.ProjectionNode[]{ Wave.QueryBuilder.get('partnerId').alias('partnerId') }; ConnectApi.LiteralJson result = Wave.QueryBuilder.load(DATASET_ID, DATASET_VERSION_ID) .filter('Id == "' + id + '"') .foreach(projs) .execute('q'); JSONParser parser = JSON.createParser(result.json); Response res = (Response) parser.readValueAs(Response.class); return res.results.records; } public class ScoreComparator implements Comparator<Record> { public Integer compare(Record r1, Record r2) { if (r1.score < r2.score) { return -1; } if (r1.score > r2.score) { return 1; } return 0; } } global class Input { @InvocableVariable public String id; @InvocableVariable public Integer targetIndex; } public class Response { public Results results; } public class Results { public List<Record> records; } public class Record { public String partnerId; } }
基本的に Dataset にクエリを投げているだけですね。
あとは上記の APEX Action を呼び出す3つの Flow を定義すれば OK です。それぞれの Flow から APEX Action に渡す targetIndex は、その Flow が担当する順位に応じて変更する必要があるため、ご注意ください。
レコメンデーションを APEX Action 経由で生成する
マッチングスコア上位の Contact の情報を説明文に埋め込みたいので、レコメンデーションは APEX 経由で作成します。具体的には Autolaunched Flow を作成し、そこから APEX Action を呼ぶことでレコメンデーションを作成します。
今回は対象者(レコメンデーション表示先)の Contact ID を Flow から渡し、その Contact のマッチングスコア上位3名分のレコメンデーションを生成するような APEX を実装しています。
global class CreateRecommendation { private static String DATASET_ID = '(your-dataset-id)'; // NOTE: 固定値ではなく REST API 経由で適宜 currentVersionId を取得するのが理想だが今回は割愛 private static String DATASET_VERSION_ID = '(your-dataset-version-id)'; @InvocableMethod public static List<String> get(List<Id> ids) { String id = ids[0]; List<Record> records = retrieveScores(id); if (records.size() < 1) { return new List<String>{'No Result'}; } records.sort(new ScoreComparator()); List<Record> top3 = new List<Record>(); for (Integer i = 0; i < records.size() && i < 3; i++) { top3.add(records[i]); } List<Recommendation> recommendations = new List<Recommendation>(); for (Integer i = 0; i < top3.size(); i++) { Record record = top3[i]; Recommendation recommendation = new Recommendation(); recommendation.Name = 'your_recommendation_' + record.id + '_' + record.partnerId; recommendation.Description = 'Talk with ' + record.partnerName + ' (ID: ' + record.partnerId + ')'; recommendation.ActionReference = 'your_flow_api_name_' + String.valueOf(i); recommendation.AcceptanceLabel = 'Go'; recommendation.RejectionLabel = 'No thanks'; recommendations.add(recommendation); } insert recommendations; return new List<String>{recommendations.toString()}; } private static List<Record> retrieveScores(String id) { Wave.ProjectionNode[] projs = new Wave.ProjectionNode[]{ Wave.QueryBuilder.get('Id').alias('id'), Wave.QueryBuilder.get('partnerId').alias('partnerId'), Wave.QueryBuilder.get('partnerName').alias('partnerName') }; ConnectApi.LiteralJson result = Wave.QueryBuilder.load(DATASET_ID, DATASET_VERSION_ID) .filter('Id == "' + id + '"') .foreach(projs) .execute('q'); JSONParser parser = JSON.createParser(result.json); Response res = (Response) parser.readValueAs(Response.class); return res.results.records; } public class ScoreComparator implements Comparator<Record> { public Integer compare(Record r1, Record r2) { if (r1.score < r2.score) { return -1; } if (r1.score > r2.score) { return 1; } return 0; } } public class Response { public Results results; } public class Results { public List<Record> records; } public class Record { public String id; public String partnerId; public String partnerName; } }
Autolaunched Flow では適当な Contact ID を取得して APEX Action に渡すようにしておきます。今回は Flow のトリガーまでは踏み込まないので、適当に実行してレコメンデーションを生成しておきます。
Recommendation Strategy Flow を作成する
最後の仕上げになりますが、特に難しいポイントはありません。Flow への入力として受け取った recordId を元にレコメンデーションを検索するだけで OK です。
サンプルコードのままであれば your_recommendation_(recordId) を名前に含むレコードを検索すれば、必要なレコメンデーションが一括で取得できます。あとは outputRecommedations にアサインすれば完了です。
Lightning App Builder で Contact のレコードページに Next Best Action コンポーネントを組み込むのをお忘れなく。
まとめ
というわけで、CRM Analytics + Einstein Discovery + Einstein Next Best Action という構成で、マッチングサービス風のレコメンデーション表示機能を実現することができました。
今回のポイントは総じて Einstein Next Best Action 関連で、
- レコメンデーション承認時の Flow から起動元の情報は得られない
- Flow で唯一入手可能なのは隠しパラメータの
recordIdのみ - 何かの上位 N 個を表示する機能は創意工夫により実現可能
というところかなと思います。なお、上位 N 個と書きましたが、表示可能なレコメンデーションは4つまでという制限があるため、実際に実現可能なのは上位4つまでの表示に限られます。ご注意ください。
今回は(も)サービスの仕様に振り回されて大変でしたが、うまく仕様上の制約を回避してユースケースの実現に漕ぎ着けたのではないかなと思っています。
実際のレコメンデーション表示画面が気に入っているので、最後にもう一度掲載して終わりにしたいと思います。(ダイマ
以上です。最後までお読みいただき、ありがとうございました。