こんにちは。エンジニアの山下です。
昨今の LLM の隆盛は目を見張るものがあり、フレクトでも LLM を使った開発に必要な技術や知識の準備を進めています。その一環として Agents for Amazon Bedrock を使って模擬的に LLM アプリケーションを実装・調整してみたのですが、今回はそこで得た知見について書こうと思います。
本投稿では主に Agents for Amazon Bedrock を使ってみて得た所見について書きますが、前提を共有するため、最初に Agents for Amazon Bedrock の概要とアーキテクチャについても簡単に述べます。既に知っているという方は読み飛ばしていただいて OK です。
Agents for Amazon Bedrock の概要
Amazon Bedrock は AWS が提供する LLM サービスですが、その提供サービスの1つである Agents for Amazon Bedrock は LLM アプリケーションの開発を支援する開発プラットフォームです。
その特徴はとにかく手軽に開始できることで、AWS コンソールでいくつかの設定を行うだけで LLM + RAG のアプリケーションが構築できてしまいます。RAG に必要なデータストアも S3 にファイルを格納しておけば自動で構築してくれる上、構築した LLM + RAG を試用するためのプレイグラウンドやデバッグのためのトレース機能もあり、開発者にとっては割と至れり尽くせりな環境です。
ただし、選択可能な LLM には制限があり、現時点ではテキスト生成に利用可能な LLM は Anthropic Claude シリーズのみで、かつ最新モデルの Claude V3 はサポート外です。利用可能なモデルは以下の3つになります:
- Anthropic Claude V2
- Anthropic Claude V2.1
- Anthropic Claude Instant V1
Claude V2 / V2.1 は高性能推論モデルで、Claude Instant は処理速度に特化した軽量モデルです。なお、Claude V3 は Agents for Amazon Bedrock では利用不可ですが、他の Amazon Bedrock のサービスでは利用可能です。
Embedding モデルは以下の中から選択可能です:
- Amazon Titan Embeddings G1 - Text v1.2
- Cohere Embed English v3
- Cohere Embed Multilingual v3
なお、Agents for Amazon Bedrock は現時点では US East と US West の2つのリージョンでしかサポートされておらず、日本リージョンでは利用できない点にはご注意ください。
Agents for Amazon Bedrock のアーキテクチャ
Agents for Amazon Bedrock で作成された LLM アプリケーションは規定のアーキテクチャに則って実装されます。以下に概要図を示します。
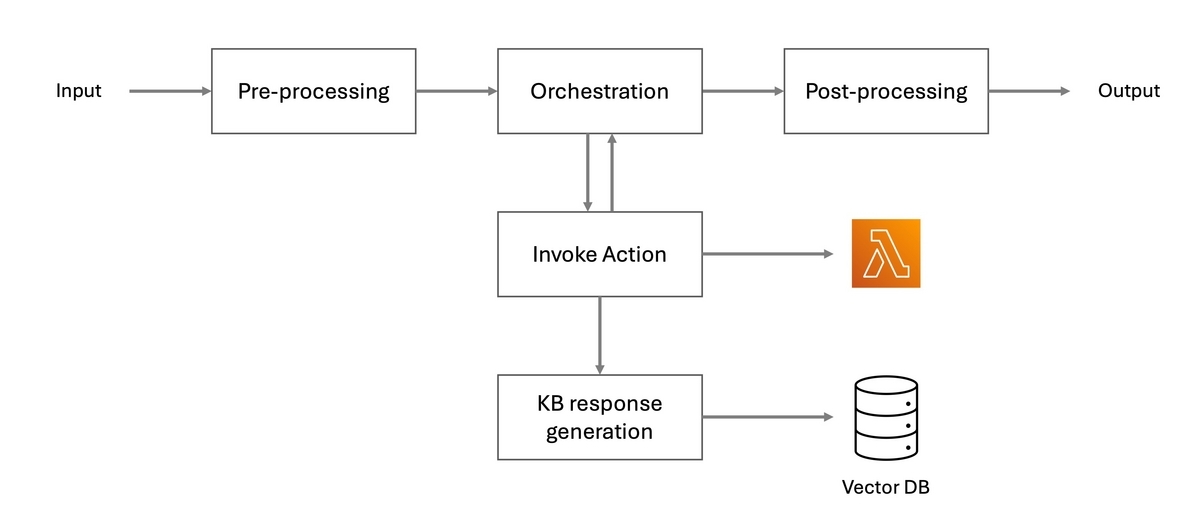
基本的には前処理・後処理にあたる Pre-processsing・Post-processing の間にメインの処理である Orchestration が挟まれている構成になっています。大まかな流れとしては、
- Pre-processing で危険な入力のフィルタリングを行う
- Orchestration でユーザへの回答の生成に必要な手順の作成と実行を行う
- Post-processing で出力データの整形などを行う(任意)
という形になります。
さらに上記 2 の Orchestration では回答に必要なデータを外部から取得することが可能で、これは図中の Invoke Action というブロックで表現されています。データの取得方法は AWS Lambda の実行ないし Knowledge Base (KB) の検索のいずれかが選択できます。なお Knowledge Base とは RAG の参照に使用されるデータストアのことで、冒頭でも少し触れましたが、基本的に S3 から生成してくれます。
なお、図中にあるこれらのブロックは全てプロンプトエンジニアリングの対象となります。Invoke Action を除く4つのブロックは Advanced Prompt と呼ばれる独自のプロンプトを持ち、また Invoke Action では Orchestration が実行要否を判断するための説明文を各アクションに付与する必要があるためです。ちなみに各ブロックで使用される LLM は全て共通(選択した Claude モデル)です。
また、プロンプトエンジニアリング以外にも Knowledge Base に格納するデータのチャンク単位や格納するデータの内容自体(文言や形式など)も LLM に合わせて調整する対象となり得ます。
実際に使ってみて感じたこと
前置きが長くなりましたが、ここからが本題です。Agents for Amazon Bedrock を実際に使ってみて得られた所見について述べたいと思います。内容は以下の通りです:
- 構築から試用までが非常に容易
- 各 Knowledge Base が単一の責務しか持たない設計が強制される
- 日本語の扱いには難がある
- LLM からの出力内容が比較的安定しない
- RAG の実行が重い
- ユーザへの質問を許可するオプションの質が今ひとつ
構築から試用までが非常に容易
冒頭でも述べましたが、とにかくアプリケーションを構築して試用するまでが高速かつ容易に行えます。Agents for Amazon Bedrock の最大の魅力がこれで、開始地点に立つまでに LLM の知識がほぼ不要なため、とにかく試したいという場合には非常に有用です。
なお、構築に必要な時間の大部分は Knowledge Base の生成で、S3 に格納されたファイルを処理して DB を構築するのに少し時間がかかります。参考までに、筆者の場合はフレクトの社員規則が書かれた 50 個程度の PDF を Knowledge Base にしましたが、構築までに数分程度かかりました。
Knowledge Base は一度構築してしまえば差分だけの更新が可能なので、更新に初期構築ほどの時間はかかりません。アーキテクチャの項でも述べましたが、格納するデータ自体も調整の対象となるため、これは結構重要です。ただし、チャンク戦略や Embedding モデルを見直す場合などは例外で、再構築が必要になるので注意が必要です。
解析環境も潤沢で、Pre-processing や Orchestration で何が行われたのかを容易にトレース可能です。また、Advanced Prompt に設定されているデフォルトのプロンプトはかなり精巧に作り込まれており、プロンプトを読むことで学ぶことも多いです。
個人的には Agents for Amazon Bedrock は LLM の学習環境という意味では随一だと思っています。
各 Knowledge Base が単一の責務しか持たない設計が強制される
アーキテクチャの項で説明した通り、Invoke Action が参照するアクションには各々説明文が付与され、その説明文に基づいた実行要否の判断が Orchestration で行われます。Agents for Amazon Bedrock では Knowledge Base の参照を Invoke Action 経由で行うため、当然ながら、Knowledge Base に対しても格納するデータの概要を表す説明文を付与する必要がありますが、これには上限 150 文字という制限があります。これは結構厳しい制約で、以下に述べる通り、Knowledge Base の構築方針を半ば強制してきます。
そもそも Knowledge Base を参照させるには、Orchestration によって「ここを検索すれば必要な情報が得られるぞ」ということを実際に検索を行う前に伝えなければならないというジレンマがあります。これは結構悩ましい問題です。
例えば、A というシステムについての情報を格納した Knowledge Base を作成し、その説明文として「この Knowledge Base には A についての情報が格納されています」という文章を与えたとします。この時、実はこの Knowledge Base が A と連携する B という別のシステムについての情報を格納していたとしても、B についてのみ言及した質問をされた場合、この Knowledge Base は参照されない可能性があります。
この問題にナイーブに対応すると、説明文を修正して「この Knowledge Base には A および B についての情報が格納されています」としたくなりますが、言うまでもなく、これは説明文の文字数を圧迫します。実は A に B 以外の複数の連携先システムが存在した場合、この手法は破綻します。
この問題を根本的に解決するためには、Knowledge Base を複数に分け、各々が単一の責務のみを持つように構成を修正するしかありません。この修正により、個々の Knowledge Base が小さく抑えられ、検索精度や検索性能の向上も見込めます。このような設計を強制するために、説明文はあえて短い文字数に抑えるという設計判断がされたように思えます。
一方で、これを行うにはあらかじめ誰かが Knowledge Base に格納するデータを責務を定めて分類しておくという作業が必要になります。これは Agents for Amazon Bedrock での作業工数を判断する際の1つのポイントになりそうです。
日本語の扱いには難がある
Agents for Amazon Bedrock で使用可能な Claude モデルは、他社の LLM に比べて日本語の扱いがやや苦手な印象があります。特に敬語の扱いが今ひとつで、以下のような問題に悩まされました。
- 敬語を使用せよというプロンプトを無視してくる
- 頻繁ではないが一定の頻度で発生する
- やたらと慇懃である
- 「〜と存じます」など
- ごく稀に発生する
- 無駄な接頭辞を付与してくる
- 「敬語を使用して申し上げます」など
- ごく稀に発生する
今回はプロンプトエンジニアリングをベースに改善を試みたのですが、結局最後まで完全に敬語を強制することはできませんでした。
あまりに敬語の強制が難しいので、敬語への変換だけを別処理として切り出して Post-processing で処理するようにもしてみたのですが、逆にやたらと慇懃な敬語に変換される等の問題が増加してしまい、プロンプトエンジニアリングや処理上の工夫だけでは完全な解決は難しいと結論せざるを得ませんでした。
最終手段として Claude にファインチューニングを施すという方法もありますが、これは極めて高価かつ手間のかかる方法なので、敬語の強制程度の話では採りたくない戦略です。それをやるくらいなら他の高性能モデルが使用できるプラットフォームを使うべきだろうという感もあり、今回はファインチューニングまでは立ち入らず、単に一定数の敬語に関する失敗は受け入れるという方針としました。
また、敬語の問題の他、RAG の検索結果に対して日本語特有の曖昧さを残す表現(〜だと思います)を使ってくることもあり、これも UX を微妙に損なうので何とかしたかったのですが、最終的には一定数は諦める方向となりました。日本語は難しいですね ... 。
Claude V3 は V2 よりも日本語の扱いがかなり上達しているように見えるので、そちらが利用可能になれば状況は変わるかもしれません。
LLM からの出力内容が比較的安定しない
Gemini などの他社の LLM と比較すると、Agents for Amazon Bedrock で使用可能な Claude モデルは出力内容がやや不安定な印象があり、モデルの気分次第で回答内容が変わります。これは Claude V2 でも Claude Instant でも同じです。
そもそも Agents for Amazon Bedrock では Temperature の値(出力内容の安定度を制御するために使用される値)が 0 に設定されており、最初から最も安定した回答が得られる設定となっていますが、それでも回答内容にはかなりのばらつきがあります。
一応、プロンプトの品質による問題の可能性もあったため、Anthropic が公開している プロンプトエンジニアリングガイド を精査して修正を行いましたが、そもそもプロンプトの指示自体がしばしば無視されるということもあり、改善されることはありませんでした。厳密な回答が求められる用途では Agents for Amazon Bedrock の採用は(少なくとも現時点で選択可能なモデルのラインナップでは)難しそうです。
また、Pre-processing で行われる危険な入力のフィルタリングにも同様の不安定さがあります。そのため、同じ内容の入力をした場合でも回答が拒否されたりされなかったりします。Pre-processing では入力を以下の A-E の5つのカテゴリのいずれかに分類して判断を下しますが、特に B や C が問題になりやすいです。
- A: 人を傷つける可能性のある入力である
- B: 情報窃盗を意図する可能性のある入力である
- C: 提供されている情報やアクションでは回答不能な入力である
- D: 提供されている情報やアクションで回答可能な入力である
- E: LLM からの質問に対する回答を意図した入力である
なお、E については、LLM からユーザへ質問を返すことを許可するオプションがあり、それを有効にした場合にのみ使用されるカテゴリとなります。
Pre-processing の不安定さは、セキュリティや反社会勢力への対応などの微妙な話題に踏み込んだ際に顕著になります。筆者の場合、フレクトの社員規則について回答する AI アシスタントを実装して評価していたのですが、自社社員からの質問という前提を盛り込んでセキュリティの基本方針について訪ねただけでも回答が拒否されるといったことがしばしばありました。意図推論は難しい問題なので、多少揺らぎがあるのは仕方ないと思うのですが、モデル自体の出力が不安定なため調整が困難という点が今ひとつに感じました。
Pre-processing に触れたので、ついでに述べておくと、Pre-processing には入力が拒否された場合に必ず英文で回答するという謎の仕様があり、日本語圏での利用を想定している場合は輪をかけて困ったことになります。具体的には以下のような文言で回答が行われます:
Sorry, I don't have enough information to answer that.
一応、こちらは API レスポンスの中身を精査することで回避可能です。具体的には、API レスポンスの気が遠くなるほど深い以下の場所に Pre-processing の合否判定結果が格納されているので、それを見て自前の出力に差し替えれば OK です。
(response).completion.trace.trace.preProcessingTrace.modelInvocationOutput.parsedResponse.isValid
レスポンスの詳細については AWS の API リファレンス を参照ください。
RAG の実行が重い
Knowledge Base が Invoke Action 経由で実行される関係上、入力に対して RAG が実行される場合とされない場合がありますが、この RAG の実行の有無の差による実行速度比がかなり顕著です。
Claude Instant を使った場合、RAG なしでの実行は長くとも数秒程度なのですが、RAG ありだと最低でも十数秒はかかるようになってきます。Claude V2 に関しては RAG が実行されると回答までに1分以上かかることもあり、boto3 のデフォルトのタイムアウト値を超えて応答待ちが打ち切られたりします。
現時点で Agents for Amazon Bedrock は US リージョンでしか公開されていないため、日本からアメリカにアクセスしているとはいえ、大部分は LLM の推論にかかる時間と考えられるため、速度面にはやや不安を覚えるという印象です。
なお、今回は試していませんが、性能改善のために Provisioned Throughput が利用可能です。Agents for Amazon Bedrock の採用を考える際の考慮事項の1つになりそうです。
ユーザへの質問を許可するオプションの質が今ひとつ
Agents for Amazon Bedrock のオプションの1つに「追加の情報収集のために LLM からユーザへの質問を許可する」というものがありますが、これは無効にしておくのを推奨します。理由は単に生成される質問の質が低いからです。
実際どれくらいの質なのかというと、ユーザが A について教えてくれと質問した場合に、A について教えてくれれば A について回答しますと答えてくるようなレベルです。既に A について知っているなら訊きはしない。
まとめ
今回得た知見をまとめると以下のようになりそうです:
- 開発環境としての質は高い
- 厳密な回答を要するユースケースへの利用は難しそう
- 速度性能に若干の不安がある
全体を通して、開発プラットフォームとしての品質は高いのですが、選択可能な LLM の性能に依存する問題が多いという印象です。LLM が不安定で性能改善が難しいという性質がある以上、現状での案件採用は少し躊躇しますが、Claude V3 が選択可能になれば可能性がぐっと広がりそうという期待感はありそうです。
また、テキスト生成モデル側は色々と問題を抱えている印象ですが、Embedding モデルについては特に大きな問題を感じることはありませんでした。筆者が試した中では Amazon Titan Embeddings G1 - Text が最良だったので、調査中はそれを継続使用していましたが、ドキュメントの検索精度は十分かなと思いました。
RAG に関しては、むしろ格納されているデータを調整する方が多かったです。一般的に PDF は RAG の参照データの形式にはマッチしていないと言われますが、これには筆者も同意です。Knowledge Base 構築時には自動的に PDF からテキストを抽出してデータストアに格納してくれますが、その際に混入する様々なノイズ(無意味な半角スペースやグラフの崩れなど)が LLM の推論精度を落とす要因となるため、結局自分の手でテキストに変換したりしていました。個人的には、この辺りの LLM 全般に関わる知見も得られたことが大きかったです。
以上です。最後までお読みいただき、ありがとうございました。