こんにちは. 研究開発室の牧野*1です. Operations Research (OR)のビジネス活用について研究を行なっています. 本稿ではORの文脈で現れる組合せ最適化問題 (Combinatorial Optimization, CO)の解法として強化学習(Reinforcement Learning, RL)を応用する研究分野(Neural Combinatorial Optimization, NCO)について紹介します. また, この分野の研究をまとめたライブラリであるRL4COを使用して簡単なデモを行います. 本稿の構成は次の通りです.
組合せ最適化問題
まず, COの定義について述べます. (※ 数式の表示が上手くいかない場合はrenderingの設定を見直すか, firefoxで開いてみてください. )
- 解空間 (Search space)
: 離散決定変数の集合
- 制約条件 (Set of constraints)
: 変数への制約条件の集合
- 目的関数 (Objective function)
: 解空間から実数への関数
このとき, 解空間上で制約条件をみたす実行可能解 のうち, 目的関数の値を最小化(最大化)する
を求めよ, というのが問題の主張です. 具体的な問題例としては, Traveling Salesman Problem (TSP), Vehicle Routing Problem (VRP)などに代表される配送計画問題, machine scheduling や shift scheduling などの scheduling問題が挙げられます. こうした問題の多くは NP困難であり, 多項式オーダーのアルゴリズムで解くことがおそらくできないことが知られています. つまり, 規模が大きくなると現実的な時間で解を最適性の保証付きで求めることが困難になります.
例として, 2次元euclid空間上でのTSPを見てみましょう. これは2次元euclid平面上で都市に対応する個の座標, つまり
個のnodeとそれらの間のユークリッド距離を重みとする完全グラフ
が与えられた時に, 移動距離(重み)の総和が最小になるような全ての都市の訪問順序(ハミルトニアン閉路)を求める問題です.
この問題での解空間, 制約条件, 目的関数がどうなるか簡潔に述べます. 解空間の取り方には任意性がありますが, ここではグラフ 上のハミルトニアン閉路全体
を解空間とすることにします. すると, ハミルトニアン閉路の定義から制約条件はみたされていることがわかります. 最小化する目的関数は
上のハミルトニアン閉路に含まれるedgeの重みの総和
です.
厳密解法とヒューリスティクス
具体的な問題例が与えられた時にその問題を解くことを考えます. まず候補として挙がるのは混合整数計画問題(Mixed Integer Programming, MIP)として定式化した後に, 分枝限定法(Branch and Bound algorithm, BB)を基礎としたMIPソルバー(汎用ソルバー)を使用することです. Gurobiを代表とする商用ソルバーの他, SCIPなどのOSSのソルバーも利用することができます. MIPソルバーの実装の詳細はソルバーによって異なりますが, 最適解を保証付きで求めることのできる厳密解法に分類することができます. MIPという抽象化された形で問題を定式化をすることができれば適用できるので, 汎用性があることがこの手法の強みです.
MIPソルバーの欠点として, 問題の規模が大きくなったときに計算に時間がかかったり, 現実的な時間で解を求めることが難しいことがしばしば起きることが挙げられます. これは前述したNP困難の性質によるものです. その際に選択肢に挙がるのがヒューリスティクス(Heuristics)と呼ばれる手法です. ヒューリスティクスでは解の最適性の保証はありませんが, その代わりに現実的な時間で実務での要求に耐える質の解を求めることができる場合があります.
課題とアプローチ
ヒューリスティクスを実務で応用する場合の課題について述べます. まず, ヒューリスティクスの設計にはアルゴリズムに関してはもちろんのこと, 問題, 業務に関する高度な専門知識が必要となります. また, 問題の設定が少し変わるだけでも設計したアルゴリズムが使えなくなる場合があり, 柔軟性や再利用性に課題があります.
課題へのアプローチとして, ヒューリスティクスの設計にRLを応用してその全て, あるいは一部を行う研究が近年行われており, これが冒頭に紹介したNCOです (Bengio et al., 2021; Mazyavkina et al., 2021). 次節以降でこの研究の中でも代表的なアプローチである自己回帰(Autoregressive, AR)による定式化を紹介します.
自己回帰を使用した手法
自己回帰について
ARの概念について簡単に説明します. 詳しくは書籍(岡谷, 2022; 瀧, 2017)などを参考にしてください. ARとはRNNをはじめとする系列を扱うネットワークにおいてある時刻における自身の出力を次の時刻での入力とすることで系列を出力していく手法のことを指します. Seq2seqをはじめとした言語モデルを中心に系列変換, 生成に関わる多くの場面で使われる手法です. Seq2seqをはじめとするモデルはencoderとdecoderからなる構造を持ちます. 直感的な説明としては, encoderでは単語の系列の深層表現を求めて, decoderでは前時刻までの出力とネットワークの現在の状態や系列の表現を考慮して次の出力を決定するといった感じです. 詳細はネットワークの構造とそれの表現する数式に依ります. 図1は代表的な例であるseq2seqの構造です. 詳しくは seq2seq, seq2seq with attention, transformer に関する書籍や記事を参考にしてみてください. 個人的にはこちらのサイトがおすすめです.

自己回帰でTSPの解を構築する
TSPを具体例にしてARで解を求めるideaについて述べます.
まず, encoderでは入力されるグラフのnode間の相関が考慮された表現を求めます. EncoderとしてはRNN, GNN, Transformer などがこれまでの代表的な研究で検討されています. 通常のseq2seqの時と違う点としては入力されるグラフが"sequence"ではなく, "set"であることです. 例えば, 個の座標を入力シーケンスとして与えることを考えると, その要素のシーケンス内における位置に意味はありません. つまり, 入力シーケンスの中で要素同士を適当に入れ替えてもそれは同じグラフを表します*2 .
次にdecoderです. Decoderではencoderの出力や現在の状態を考慮しながらARで逐次的に次に訪問する都市を求めていきます *3*4. Decoderのある時刻での出力を正確に表現をすると, その時点までに訪問済みの都市の一覧が与えられた時にそれぞれの都市が次に訪問される条件付き確率です. 例えば, 既に訪問された都市が訪問される確率は0になるようにします. このあたりのモデリングはseq2seqと同じ発想なので, そちらも参考にしてください.
Encoderとdecoderをまとめてみると, あるグラフが与えられた時に, そのグラフ上でのあるハミルトニアン閉路
が出力される確率
を表現するネットワークになっています. ここで,
はネットワークを特徴づけるパラメタです.
上のハミルトニアン閉路
のeuclid距離を返す関数を
とすると, 最適なパラメタ
は
を解くことで得ることができます. ここで, はグラフの生成分布です. 本稿では先行研究と同様にして
の領域(unit square)からランダムにグラフを生成するものとします.
このパラメタをRLを使用して学習します.
なぜ強化学習なのか?
過去には教師あり学習(Supervised Learning, SL)でARモデルを学習する研究 (Vinyals et al., 2015) もありましたが, Bello et al., 2016でRLが導入されて以降はこれが主流になっています*5. SLの場合は学習データとして多くの問題インスタンスとその解が必要になります. しかし, そもそも解を求めることが難しい問題を扱おうとしているので, 既に優れたヒューリスティクスがある問題でないと学習データを用意することができないというのが問題です.
その一方で, RLの場合は解の構築を試行錯誤する中で自律的に学習することができます. つまり, 解を事前に用意する必要がなく, 適用範囲が広くなります. NCOの分野ではREINFORCE, PPO などのpolicyベースの手法が取られることが多いです. RLの詳細については代表的な教科書(Sutton and Barto, 2018), OpenAI Spinning Up などを参照してください.
RL4CO
RL4COの概要
RL4COは前節で紹介した一連のARモデルによるNCOの研究を中心に整理してまとめられたライブラリです. これまでの研究について考察し, 共通化できる部分をモジュールとして切り出すと同時に, NCOの分野における実装, 実験のベースラインを提供しています. Pytorch Lightning, TorchRLを利用した再利用性の高いコード, Hydraを用いた設定の管理が特徴です. これまでの研究の結果を手軽に再現できると同時に, NCOへの理解を深めることができます. 自分で何か新しいモデルやアルゴリズムを実装する際も用意されたインターフェイスを継承することで恩恵を受けることができます.
RL4COを使ってみる
RL4COを使用してTSPを Kool et al., 2020 の手法で解くためのサンプルコードを紹介します*6. 専門的な知識がなくてもコード自体は手軽に動かせますので, ぜひ自身の手元で動かしていただければと思いますが, できればGPUがあることが望ましいです.
import torch from rl4co.envs import TSPEnv from rl4co.models import AttentionModelPolicy, REINFORCE from rl4co.utils.trainer import RL4COTrainer # Env: RL4COで用意されているTSPのenv. 50都市で用意 env = TSPEnv(generator_params={'num_loc': 50}) # Kool et al., 2020 で提案されたencoder-decoderモデルの実装 # 大雑把には位置符号化のないTransformer policy = AttentionModelPolicy( env_name=env.name, embed_dim=128, num_encoder_layers=3, num_heads=8, ) # RL Model: RLのアルゴリズムを指定する. # 詳細は Kool et al., 2020. を参照 model = REINFORCE( env, policy, baseline="rollout", optimizer_kwargs={"lr": 1e-4}, ) # Trainerの用意 trainer = RL4COTrainer( max_epochs=3, accelerator="gpu", devices=1, ) # モデルの学習 trainer.fit(model)
このコードでは50都市からなるTSPのインスタンス群を作成して3-epochほど学習をしています. 学習の詳細なパラメタなどは実装を参照するようにしてください. 筆者がGoogle Colaboratoryでも利用できるT4 GPUを使用して実験したところ, 3分ほどで学習が終わりました. また, これらの設定はHydraで管理されているので, プロジェクトルートから下記コマンドを実行することで同様の実験を行うこともできます.
python run.py experiment=routing/am env=tsp env.generator_params.num_loc=50 model.optimizer_kwargs.lr=1e-4
結果
図2が2つのインスタンスに関して学習したpolicyから出力される経路を確認した結果です. 左側が学習していないpolicy, 右側が学習したpolicyからそれぞれgreedyに経路を計算*7したものになります. 学習をした後は期待されるように生成されるルートの総距離(cost)が短くなっていることが見て取れます.
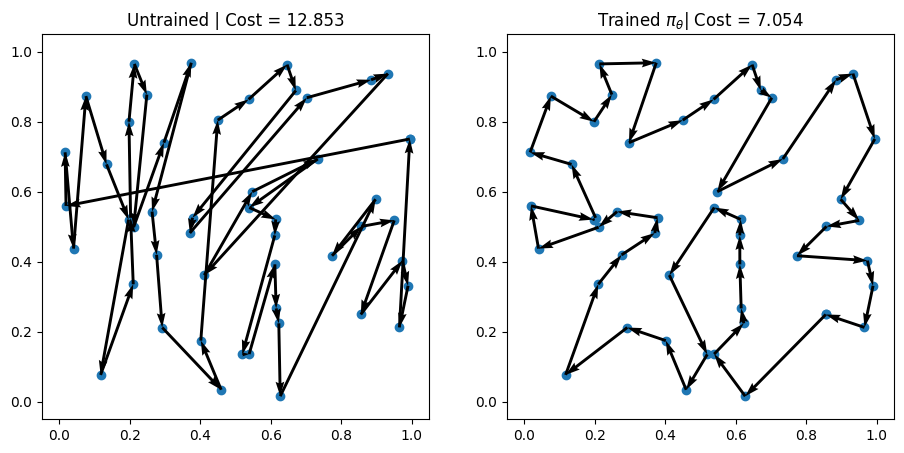

また, 学習済みのpolicyからgreedy decodingで解を求めるのにかかる時間は1秒未満でした. 一方で, 手元のM1 MacBook Pro 2021を使用してSCIPで50都市からなるTSPを解いた場合にかかる時間は約1分でした. 都市の数がさらに多くなるとこの計算時間の差はより顕著になると予想されます. 実際に80都市からなるTSPで同様の実験をしたところ, SCIPでは60分でも解けていませんでしたが*8, NCOでは学習に7分, greedy decodingは約1秒でした. 直感的には都市数を としたときに, greedy decodingの計算量は
に比例して増えていきますが, BBでは決定変数の数が組合せのオーダーで増えていくことで理解ができそうです.
このように学習をする必要はあるものの, それができれば短時間で解を求めることができるのはこの手法の魅力的な点の1つです.
補足: Active Search
前節で紹介した例では学習したモデルから推論をする形をとっていますが, 実務では実際の問題インスタンスが訓練時に使用した分布から外れたり, そもそも学習用のデータが手に入らないことが考えられます. このような場合に有効になるのがActive Search(AS) (Bello et al., 2016; Hottung et al., 2022)と呼ばれる手法です. 学習を"Learning algorithms to infer from data to learn new task." であるとすると, ASは単なる最適化に近いものであると筆者は考えています. ASはRL4COにも実装されていますので, そちらも参考にしてみてください.
まとめと今後の展望
本稿ではCOのヒューリスティクスの構築にRLを応用するNCOと呼ばれている研究分野について紹介しました. 現状ではヒューリスティクスの設計は高度な専門性が必要とされる分野ですが, NCOが発展することで負担を軽減し, その手続きに再現性を持たせることができると考えています. 現状ではTSP, VRPなどの代表的な問題を中心に研究がされているので, scheduling問題をはじめとするその他の問題についても今後考察をしてみたいです. また, ARによるアプローチはend-to-endな手法ですが, 既存のメタヒューリスティクスの一部をRLで補助するような研究(Ye et al., 2024)にも注目をしています. この記事ではNCOの概要しか紹介をすることができませんでしたが, 興味を持っていただけた方はこれまでの論文やRL4COのドキュメントをぜひ見ていただきたいです.
最後に
最後まで読んでいただきありがとうございました.Flect では今後もお客様にとって付加価値となるような新たな分野や技術に関して開拓を行っていきます.今回紹介したNCOの他にも様々な OR の諸問題に関しても研究を行っているため,もしご興味がありましたら是非ご相談ください.
*1:2022年度新卒入社. 学生時代は理論物理, 特に物性理論と呼ばれる分野で研究をしていました.
*2:細かい話: Transformerだとこの対称性を自然に考慮することができるのですが, RNNベースだとBello et al., 2016 でも触れられているように大変だったりします.
*3:ヒューリスティクスの分野では constructive algorithmsと呼ばれる手法があるのですが, 逐次的に解を構成していく部分に類似性があります.
*4:お気持ち的にはこんな感じの捉え方ができますが, 実際の研究ではattentionの活用をはじめとする様々な工夫がされています.
*5:Bello et al., 2016では Vinyals et al., 2015 で提案されたPointer Networks をRLを使用して学習しています. Pointer Networksはattentionの計算が入力シーケンスの長さに動的に対応できることを活用しています. RLとattentionの活用がこの分野の重要なポイントです.
*6:公式のexampleに記載されているものとほぼ同じです. また, RL4COは開発中のため公式の最新の状況を確認してください.
*7:Greedy decodingの他にもsamplingなどの様々なdecoding schemeがあります.
*8:Objectiveの値を見て途中で打ち切るなどの方法も考えられます. 今回は単純に比較をしましたが, 本来は様々な注意を要します. そもそも解くの意味合いがやや異なります.