こんにちは。エンジニアの和田です。
今回は、AIエージェントに既存のデータをいろいろ接続してみた結果見えてきた課題について解説したいと思います。
AIエージェントは、AI自身が自律的に判断してタスクを実行していくわけですが、自律的に判断するためにも、タスクを実行するためにも、LLMに閉じた世界では足らず、何らかの形で外部と接続することが不可欠になってきます。
特に、LLMに学習されているもの以外の知識を注入するのに、特定のデータと接続することは重要になってきます。Vector DBを作成してベクトル検索によりRAGを行うことはその代表例でしょう。
弊社社内では、「ポメ子」というAIエージェントを構築し活用しています。これは社内の情報システムに関する問い合わせに一次回答するものですが、この「ポメ子」においても、接続するデータを増やしていくことで、対応できる範囲が拡大してきています。
しかし、いくつかのデータに接続してみたところで、課題も見えてきました。 こういった課題は、実際にデータに接続してみたことでわかる面もあるかと思い、今後読者の皆様がAIエージェントを作るにあたって参考になる部分もあるかと思います。 そこで今回は、これらの課題について解説します。
なお、ポメ子はAgentforceで構築しているので、本記事は一応Agentforceを念頭に記述しますが、Agentforceでの構築に限らず一般のAIエージェントに当てはまる内容なのではないかと思います。
ポメ子の概要
ポメ子は、すでに述べた通り、社内の情報システムに関する問い合わせに一次回答するAIエージェントです。具体的には、社員がSlackの問い合わせ専用チャンネルに問い合わせを投稿すると、ポメ子が回答できる場合には自動的に返信し回答します。回答できない場合は、代わりに情報システム部の担当者が回答することになっています。
当初は、過去のSlack上での情報システム部への問い合わせのデータのみを接続していました。具体的には、過去のSlack上での情報システム部への問い合わせの投稿をVector DBにし、新たに問い合わせが投稿された場合、過去に類似質問がないかVector DBをハイブリッド検索して調べ、その回答を抽出してユーザーに示す、というものです*1。
これでも一定程度の質問には回答できたものの、回答できる範囲を拡大すべく、さらに接続するデータを増やすことにしました。
まず、Backlog*2のデータに接続しました。具体的には、社内の情報システムに関する申請が含まれている過去のBacklog課題チケットをVector DBにし、問い合わせに対して、申請が必要そうなものに関しては、過去に類似の課題チケットがないかVector DBをハイブリッド検索して調べ、あればユーザーに提示する、というものです*3。
また、Web検索にも対応しました。問い合わせに対して、Web検索が有用と認められる場合(例えばWindowsの一般的な使い方など)、適宜Web検索をしてユーザーに提示するようにしました。これは自前で持っているデータではありませんし、Vector DBを用いたRAGではありませんが、広い意味で外のデータと接続しているという観点ではこれまでの機能と同様です。
見えてきた課題
以上の対応を行った結果、回答できる範囲が拡大したのは確かです。 しかし、いくつかのデータに接続してきたからこそ、見えてきた課題があります。
検索すべきデータの選択を誤ることがある
特に運用に関する質問と仕様に関する質問を混同してしまうケースが目立ちました。例えば以下のような問題です。
- Slackコネクトを特定の条件下で使う場合の社内申請について尋ねているのに、Web検索してSlackコネクトの一般的仕様について答えてしまう(運用の質問を仕様の質問と勘違いしたケース)
- Teamsの参加招待を受けたのに入れないという問い合わせなのに、Backlog課題チケットを検索し、チーム招待の過去申請について答えてしまう(仕様の質問を運用の質問と勘違いしたケース)
Backlog課題チケット検索は、弊社の場合、社内の情報システムに関する申請が含まれているため、運用に関する質問に向いています。一方、Web検索は、社内固有のルールではない一般的な知識を検索するため、仕様に関する質問に向いています。ここを取り違えると、誤った回答につながってしまうというわけです。
これは、特定のキーワードに反応しただけだったために起こった現象とも言えそうです。「Slackコネクト」「招待」という言葉に引きずられすぎたようにも見えます。
考えられる対策としては、接続先の選択に関するプロンプトを強化することが挙げられます。すでにポメ子には、Backlog検索すべきか、Web検索すべきか判定するプロンプトは組み込んでいましたが、より強固にするため、例えば「運用に関する質問の場合はBacklog課題チケット検索を試す」「仕様に関する質問の場合はWeb検索を試す」*4といった方針を明確に記述することが考えられます。
ユーザーの課題を解決しない検索結果をそのまま提示してしまう
検索で得た結果がユーザーの前提や状況に合わず、課題解決につながらないケースがあります。
例えば以下のような問題です。
- 物理的なノートPCのOffice導入について尋ねているのに、EC2上のOffice導入に関する過去質問を持ってきてしまう
- PCがつかないという問題で強制再起動をすでに試したとユーザーが言っているのに、PCがつかない問題に関する過去質問を持ってきて、強制再起動を指示してしまう
いずれも、部分的なキーワード一致により、過去質問に対するハイブリッド検索では相対的にスコアが高く出たのでしょう。しかし前提条件が異なるため、ユーザーの課題解決にはつながっていません。
この問題は、検索結果が真にユーザーの課題を解決するかどうかを判定する機構が不十分であることを示唆しています。単に検索すればよいのではなく、得られた結果を再評価し、課題解決につながらない場合は別の手段を模索するか、無理に回答しない(ポメ子は回答できるときだけ反応する仕様のため)といった制御を加えるよう、プロンプトを調整する必要がありそうです。
明確にデータ化されていない知識が必要になる
例えば以下のような問題です。
- 社内システムに特定の名前を付けているが、その名称を挙げた問い合わせが来ても、その名称が社内システムを指すことや、システムの詳細をエージェントが知らないため、適切に回答できない
- Windows PCに関する問い合わせが来た際、弊社では特定メーカーの製品のみを採用しているため本来はそのメーカーに特化した対処を提示したいが、その前提を知らないため適切な回答ができない
- 「こういう問題が発生するので端末交換させてほしい」という問い合わせに対し、端末交換せずに解決できる方法があっても、それを先に提示できず、すぐに端末交換の回答をしてしまう
これらはいずれも、社内ではほぼ常識となっている知識が大半であり、改めて文章化されることもないのですが、そこが落とし穴となってエージェントが適切に回答できない状態となっています。
これに対応するには、個別具体的な知識を一つずつ整備して取り込んでいくしかなさそうです。
考察
以上見てきた課題から言えることとして、「より精度を上げようと思ったら、単にデータの接続先を増やすだけでなく、地道な調整が必要となる」ということが挙げられます。
これまでは、既存のデータ(Web検索も広い意味で既存のデータを用いた検索と言えるでしょう)をそのまま活用して接続することで対応範囲を拡大させていきました。
しかし、それだけでは限界があり、この先は、プロンプトを地道に調整してエージェントの動きを制御したり、個別具体的な知識を一つずつ取り込んだりする必要があるとわかりました。
ところが、ここで一つ問題が発生します。
それは、この先は、エージェントの性能を高めるために必要なコストが増大してしまうことです。
これまでデータの接続先を増やしていましたが、増やせば確実に回答できる範囲が増えることが明確でした。それに、既存のデータを活用するだけであれば、データ自体を用意するコストはかからずに済みます(そのデータをうまく繋げるためのコストはかかりますが)。
一方、地道にプロンプト調整するとなると、開発コストをかけてどれだけ改善するかは不透明になってしまいます。AIエージェントの動きは非決定的ですから、100%を目指そうとすればするほど大変になっていきます。
また、個別具体的な知識を入れるとなると、データを用意するコストが新たに発生します。さらに、これまでほぼ一般論でやっていたところ、個別具体的な知識に着手するとなると、それだけ対応できる範囲が狭い部分に着目することとなり、どうしても効率は落ちてしまいます。
まとめると、データの接続先を増やしていく段階では確実に回答率が上がるが、その段階を過ぎると伸びが鈍くなり、100%に近づくほど厳しくなっていく、という形になります。
グラフにすると以下のようなイメージです。
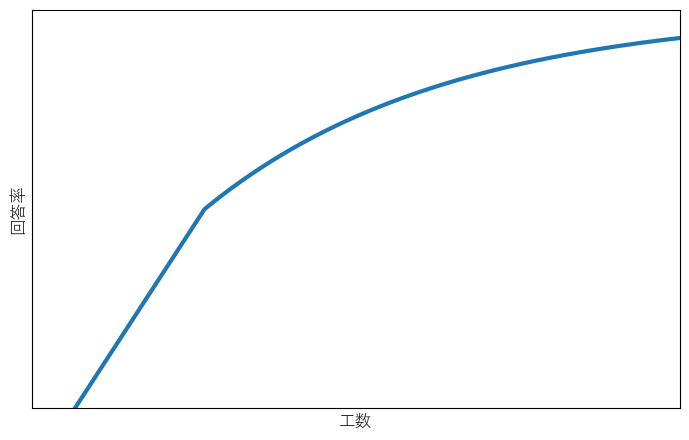
このように、単なる技術の問題にとどまらず、どこまで投資するかという経営的判断も関わってきそうです。
おわりに
以上、ポメ子の開発においていくつかのデータに接続した結果見えてきた課題について述べてきました。また、見えてきた課題は、単にデータ接続を増やしていた段階よりも一段ハードルが高いこともわかりました。なんとなく「単純に接続しただけでは限界があるだろう」と予測できたとしても、具体的にどのような課題が出てくるかは、実際に接続してみたからこそ実感を持って見えてきた面もあると思っています。
読者の皆様がAIエージェントを作ろうとなったときに、本記事で挙げた課題が発生し得ることを頭の片隅に置いておくだけでも違うのではないかと思います。
最後までお読みいただきありがとうございました。
*1:具体的な技術要素を挙げて解説すると以下の通りです。まずMuleSoftを用いて、Slack APIを呼んでSlack投稿を取得し、S3にアップロードします。S3のデータをData Cloudで取り込んだ後Search IndexでVector DBを作成します。このVectorDBを検索するRetrieverを使いつつ回答も取り込むFlowを含めたPrompt TemplateをAgent ActionとしてAgentにつなげています。
*2:株式会社ヌーラボが提供するプロジェクト・タスク管理ツールです。https://backlog.com/ja/
*3:具体的な技術要素はSlackの問い合わせデータのときとほぼ同じであり、Slack APIの代わりにBacklog APIをMuleSoftで呼んでいる以外はほぼ変わりありません。
*4:ただし、仕様に関する質問であっても、内部システムの問題で外部に公開されていない仕様の場合はWeb検索の意味がないため、注意が必要です。