こんにちは。研究開発室の岡田です。
前回の投稿でAmazon Chime SDK*1のVideo Processing APIを使って仮想背景を実現する方法をご紹介しました。この中では人物と背景のセグメンテーションをBody Pixを用いて行っていました。今回は、より軽量といわれているGoogle Meetのモデルを用いて仮想背景機能を実装、評価してみたいと思います。
こんな感じに動きます。
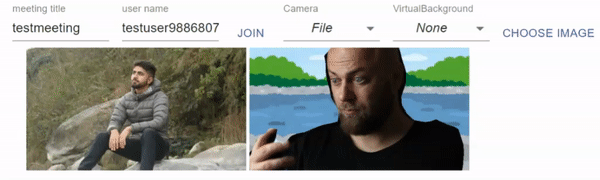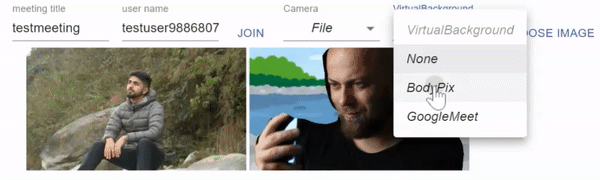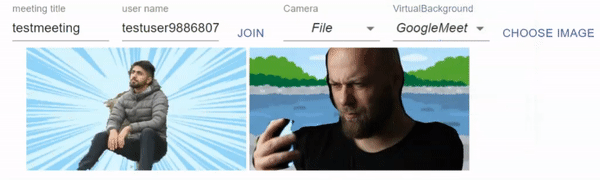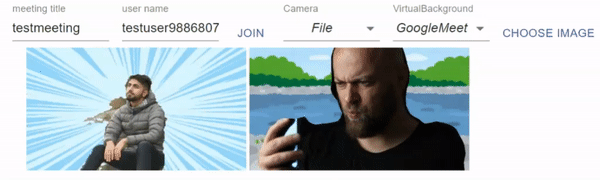
2021/03/28:M1 Macでの追加検証を追記しました。また、BodyPixのアップデートにより処理時間が変わったのでアップデートしました。
Google Meet Virtual Background
2020年10月のGoogle AI BlogでGoole Meetの仮想背景に関する記事が公開されました。ネイティブアプリではなく、ブラウザ上のアプリでの仮想背景機能にもかかわらず、高速かつ高精度であったため大きな話題となりました。この高速、高精度を実現するために、様々なアイデアが取り込まれています。概要としては下記のようなものとなります。

この機能はMediaPipeというフレームワークで作られています。この仮想背景機能では、ニューラルネットワーク内の浮動小数点計算を効率的に処理するXNNPACKとTFLiteを用いて、セグメンテーション用のモデルを動かしています。また、モデルへ入力する画像の解像度を小さくすることで、モデル内の計算量を減らして推論を高速化しています。モデルは、MobileNetV3-Smallをエンコーダに使うEncoder-Decoder構造のアーキテクチャとなっています。Encorder(MboleNetV3-Small)の部分は、NASによって少ない計算リソースで動くようにチューニングされているようです。 モデルへの入力の解像度を下げた結果としてセグメンテーションの精度が劣化することが想定されますが、これを補うために、後処理でJoint Bilateral FilterやLight Wrappingといった補正処理を行っています。この後処理は計算能力の高くないデバイス上ではスキップすることもできます。
より詳細にはGoogle AI Blogを参照していただきたいですが、こちらの記事もわかりやすい解説をされているのでご参照いただくと理解が深まるかと思います。特に、今回、しれっとスルーした後処理部分についてはとても参考になります。
Google Meet Segmentation ModelのTensorflowjs(TFJS)変換
前述の通り、Google Meetの仮想背景はMediaPipeのソリューションとして作成されています。Media Pipe自体はOSSで公開されているのですが、Issueを見るとJavascriptのソースコードについては公開する予定がないようです。MediaPipeソリューションの一部はAPIとして使えるようになってきているようですが(Issue, Issue)、仮想背景機能についてはまだ公開されていないようです。
一方で、仮想背景機能の内部で使用されているセグメンテーションのモデル(tfliteフォーマット)については、Apache-2.0のライセンスで公開されています(2021/2/2現在、ライセンスが変更されたようです。*2)。このモデルはGoogle Meetの仮想背景を実現する一部でしかないので、このモデルを用いたところでGoogle Meetと同等のパフォーマンスを実現することはできません。しかし、上記の通り、このモデルは少ない計算リソースで動くようにチューニングされており、その恩恵は受けることができる可能性があります。
tfliteフォーマットのモデルは、そのままではTensorflowjsでは使用できないのですが、中の重みを取り出して処理(Operation)をTFLiteのものからTensorflow標準のものに置き換えることで Tensorflowjsで使えるように変換することができます。この手順はPINTO氏のブログで詳しく解説されていますのでご参照ください。今回は、公式なtensorflowjsのモデルではないですが、PINTO氏作成のモデルを用いて仮想背景機能を作成したいと思います。
Google Meet Segmentation Model TFJS版を用いた仮想背景
Google Meet Segmentation Modelは入力解像度の異なる3つのモデル(128x128, 96x160, 144x256)を公開しています。それぞれを用いた結果を示します。上段が後処理なしで、下段が後処理をしたものになります。なお後処理は簡易実装版となっています。

全体的にほとんど差はでないようです。128x128の画像だと女性の左側の頭上部分が少し乱れていますが、96x160の画像 、144x256の画像の順番に少しずつ改善しています。後処理をしてしまうと、ほとんど見分けがつかないレベルだと思います。
次に、BodyPixとの比較を見てみます。BodyPixには様々なパラメータがあるのですが今回はすべてデフォルト値を使いました。入力する画像の解像度は可変でデフォルト値がないので480x640にしています(BodyPixのリポジトリのサンプルで使われているため)。 バックボーンはMobilenetV1とResnet50の両方を試しています。(1)の画像はGoogle meetのモデル128x128を用いたもので、後処理がないものです。(2),(3)はBodyPixを用いた画像です。(4)はGoogle meetのモデル144x256を用いたもので、後処理をしたものです。

(2)MobilenetV1のBodyPixはわずかではありますが粗があり背景が見えてしまっています。(3)ResNet50はさすがというべきか、かなりきれいに背景を消してくれています。しかし、(1)Google meet(128x128, 後処理なし)もギザギザにはなっていますがResNet50に引けを取らないレベルかと思います。後処理を含めて比較するとフェアではないですが、(4)Google meetの144x256モデル後処理ありがこの中で一番きれいに見えると思います。
今回はIOUの比較などはやりませんので定量的な判断はできませんが、画像を見ていただいただけでもかなりの精度があるとわかっていただけるかと思います。
処理時間の評価
処理時間を見てみたいと思います。下図は仮想背景の処理の概要です。まず、カメラの画像をテンソル化してGPUにアップロードします。その後、正規化などの前処理を行います。前処理が終わると推論を実行し、結果をCPUにダウンロードします。結果に対して後処理を施してからレンダリングを行います。今回の処理時間は次の3つの範囲を評価したいと思います。(a)はモデルの推論時間のみです。(b)はGPU内で行う正規化などの前処理と推論結果のダウンロードまでの時間です。(c)は後処理まで含めた処理時間です。今回はBodyPixとの比較を行いますが、BodyPixでは(a)の部分は隠蔽されているので取得できません。今回は(b)と(c)で比較することになります。

今回処理時間の計測に用いたのはMacBook Pro 2019の2.4Ghz QuadCore Intel Corei5です。Google AI Blogでは、MacBook Pro 2018の2.2GHz 6Core Intel Corei7を用いて評価していました。すこし環境が異なりますが、参考にはなりそうです。 今回は下記のような結果になりました。 (TFJSのバージョンとBodyPixのバージョンを上げたところBodyPixの場フォーマンスが上がったので結果をアップデートしています*3。また、GoogleMeetの後処理も効率化しました。2021/03/28)

(a)については、すべてのGoogle Meetのモデルで8~9msでした*4。Google AI Blogでも8.3ms程度で推論ができているとのことなので、ほぼ一致しています。
(b)については、Google Meetのモデルは22.0~28.5msでした。細かく見るとGPUの処理結果をCPUへダウンロードする処理でデータ量に比例して時間がかかっているようです。BodyPix MNv1は55.2mかかっており、BodyPix Resnet50では114.4mもかかっていました。しかしこれは、解像度が大きい640x480の画像を入力しており、結果も同様の解像度となるため結果のダウンロードに時間がかかっている可能性があります。そこで、新たなケースとしてBodyPix MNv1に300x300の解像度の画像を入力してみました((6)のケース)。結果、34.5msまで処理時間を短縮することができました。しかし、解像度を落とした分だけ、結果は劣化してしまいます。下図がその結果となります。だいぶ背景が見えてしまっています。

(c)は、どのモデルも40ms弱といったところです。後処理が推論と同じ程度の時間を使ってしまっていますが、ここは簡易版の処理なのでまだ改善の余地があるかと思います。しかし、それでも凡そ25FPSで処理できます。BodyPixは(6)のケースであればほぼ同等の性能ですが、前述の通り少し精度が荒い結果となってしまいます。
なお、前述の通り、Google Meetの仮想背景では低リソースのデバイス上では、後処理をスキップすることも想定しています。スキップした場合の処理時間も(3)-p.p.の行に示しています。23~27msの処理時間となっています。低解像度を入力する(6)の6割ほど高速に動きそうです。なお、前述のとおり、後処理をスキップしてもかなりの精度のセグメンテーションができています。
以上から、Google Meetのセグメンテーションモデル TFJS版を用いることで、(MediaPipeのフレームワークを使用しないでも、)次のようなことが言えそうです。
- 低スペックなデバイス上:後処理をスキップすることで、BodyPixより高品質で6割程度高速な仮想背景が実現できる。
- 高スペックなデバイス上:後処理を実施することで、BodyPixと速度は大きく変わらなくても、かなり高品質な仮想背景が実現できる。
※ BodyPixはMNv1を用いて300x300程度の低解像度の入力を行う想定。
処理時間の評価(追加検証)
本ブログを公開したところ、UMA(UnifiedMemoryArchtecture)を採用しているM1 MacならGPUからCPUへのメモリ転送のオーバヘッドがなくなるので、もっと高速になるのではないか、というご指摘をいただきました。なるほど!ということで、せっかく買ったのにほとんど使用していない自前のMac Book Air(M1モデル)で試してみました。結果は次のとおりです。全体的に高速化されているのは想定通りです。一方、UMAにより、Google Meetを用いた場合に(a)と(b)の差がほぼなくなることが期待でしたが、残念ながら依然として残っています。この結果から、(a)に対し(b)の時間が長いのは、どうやらGPUからCPUへのメモリコピーがオーバヘッドになっていたのではなく、GPUでの処理を同期するところで待ち合わせしていたからと考えたほうがいいかもしれません。

デモ
評価に用いたデモはこちらから試していただくことができます。
Amazon Chime SDKによる仮想背景の実装
Amazon Chime SDKのVideo Processing APIを用いた仮想背景の実現方法は以前の記事でご紹介した通りです。BodyPixをGoogleMeetのモデルに置き換えれば実現できますので、ここでは実装の説明は省略します。詳細を知りたい場合は、後述するリポジトリをご参照ください。 動作の様子は次のような感じになります。
リポジトリ
今回評価に用いたデモのソースコードは次のリポジトリにおいてあります。
https://github.com/w-okada/image-analyze-workers
また、Amazon Chime SDKの仮想背景のデモは次のリポジトリにおいてあります。
https://github.com/w-okada/chime-videoprocess-ts
まとめ
今回は、Google Meet のsegmentation modelをTFJS化したものを用いて、Amazon Chime SDKにより仮想背景機能を実装しました。そして、BodyPixとの比較評価の結果、(MediaPipeを用いている本家のGoogle Meetの仮想背景機能には程遠いが、)BodyPixより高速かつ高品質な仮想背景を実現できそうなことがわかりました。
なお、上述の通り、今回は公式のモデルではなく有志が公式のTFLiteのモデルをTFJSに変換したものを使用しています。使用は自己責任においてのみとなりますので、ご注意ください。特に製品に組み込むには特段の注意と品質確認が必要かと思います。また、今回はGPUで動かすことを想定しています。WASMでは推論が動いた実績はありません。もうしばらくの改善を行う必要がありますのでご注意ください。
最後に
弊社FLECTは、Salesforceを中心にAWS, GCP, Azureを用いたマルチクラウドシステムの提案、開発を行っております。 また、ビデオ会議システムとしては、Amazon Chime SDKを中心とした各種ビデオ会議用SDKを用いたシステムの開発しており、サービス化の実績もあります。 ご興味をお持ちいただけたら是非ご相談ください。
また、FLECTでは、次世代ビデオ会議システムの機能開発を進めており、Amazon Chime を用いたテストベッドを作成しています。 このテストベッドでは、ここで紹介した機能以外にも、チャット機能やホワイトボード機能も搭載しています。 またCognito連携も実装しています。下記のリポジトリに公開しています。
https://github.com/w-okada/flect-chime-sdk-demo
謝辞
人物の画像、人物の動画、背景画像はこちらのサイトの画像を使わせていただきました。
